ACL 2017入选论文,作者为来自斯坦福的Danqi Chen(cs224n助教)。Facebook于2017.7.27日开放源码,项目名为DrQA。
DrQA的主要任务是大规模机器阅读(MRS)。DrQA会在一个非常庞大的非结构化文档语料库中寻找问题的答案。这个系统最大的挑战是文档检索与文本的机器理解如何更好的结合。
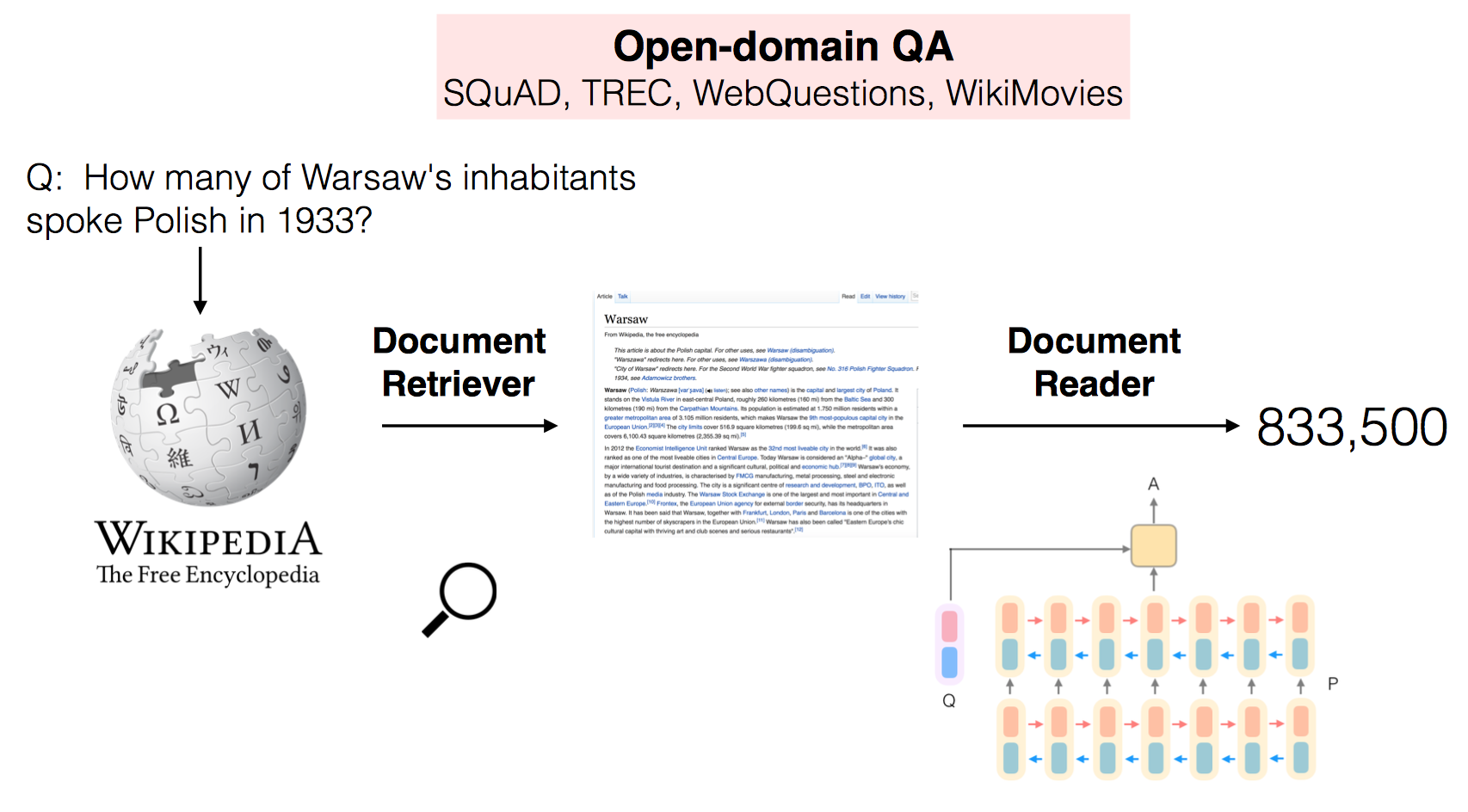
文档检索
采用基于二元语法哈希(bigram hashing)和TF-IDF匹配的搜索方法。
文档阅读理解
篇章和问题均采用三层双向LSTM,128个hidden units进行编码。
篇章编码
Word embedding
GloVe, 300-dimensional
Exact match.
篇章中的某个词的原始、全部转换为小写和形态上是否匹配。
Token features.
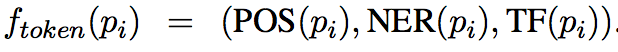
Aligned question embedding.
与问题计算注意力权重后获得的特征。
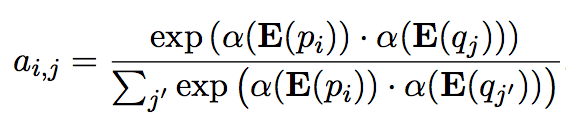
问题编码
使用一个需要学习的权值向量计算问题各个单词的注意力权重,然后加权求和作为问题的整体表示。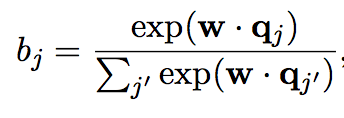
预测
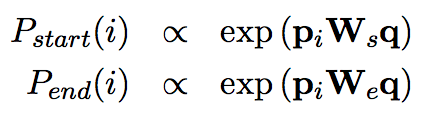
获得篇章单词与问题的相似度结果后,选择Pstart(i)×Pend(i′)最大的作为答案开始坐标和结束坐标,坐标之间即为答案,同时可利用i ≤ i′ ≤ i+15限制答案长度。