科大讯飞与哈工大联合实验室最近(截止2017.8.9)在SQuAD数据集上的准确率夺得全球第一名,力压微软亚洲研究院。本篇论文是该实验室在2016年发布的,是模型的早期版本。印象中当时在SQuAD榜单上single model准确率第二名,整体排名大概是第7名,F1 score约为79+,此处信息有待核实。准确率第一名的模型为“Interactive AoA Reader”,基于交互式层叠注意力。主要思想是根据给定的问题对篇章进行多次过滤,同时根据已经被过滤的文章进一步筛选出问题中的关键提问点,交互式地精确划定答案的范围。个人猜想其思想与斯坦福大学CS224n公开课Lecture 16中提出的Dynamic Memory Network基本一致。由于新模型的论文可能暂时没有发表,这里先对早期模型进行一下总结。
任务描述
面向完形填空型阅读理解任务,可利用一个三元组表示:
模型结构
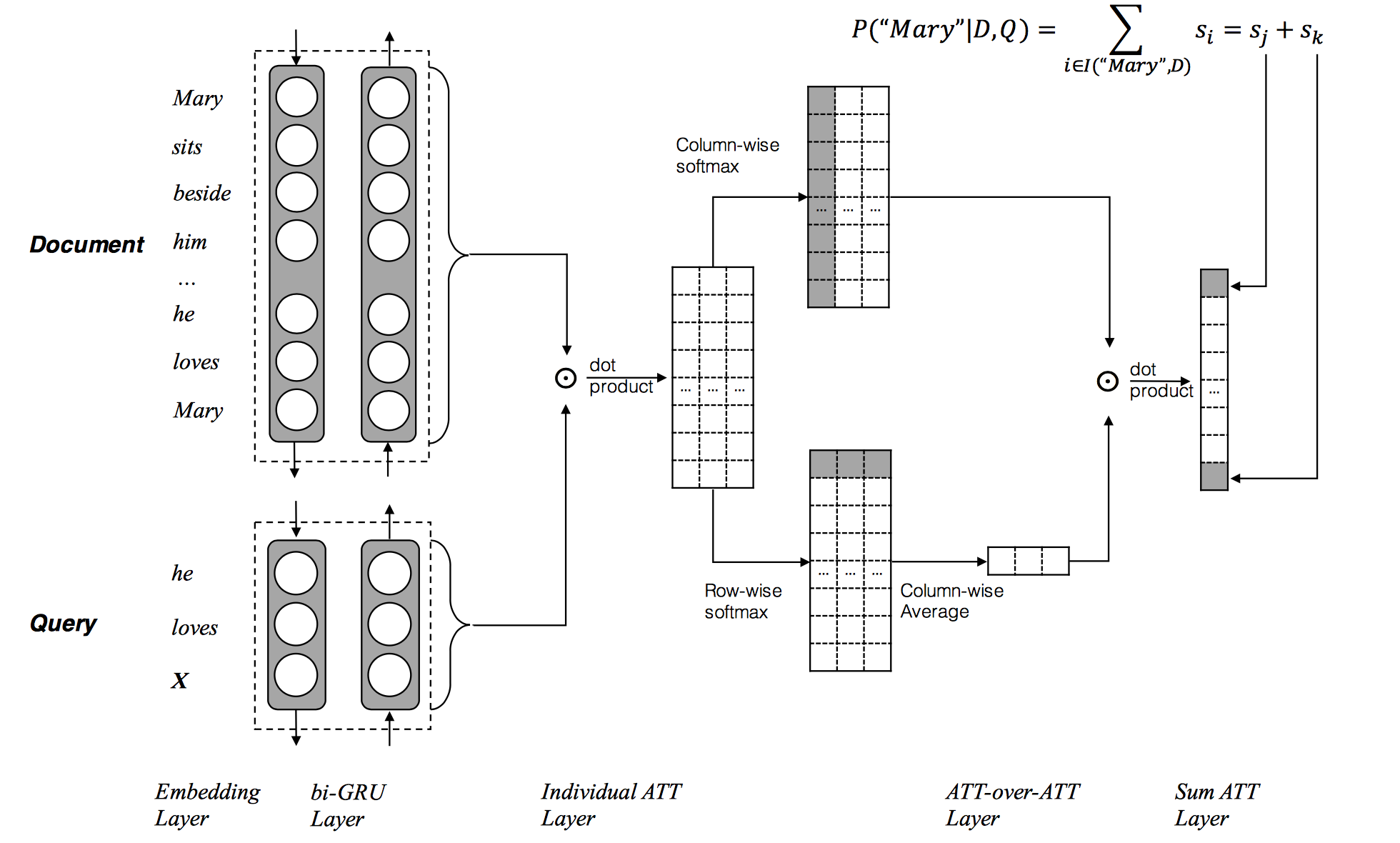
模型主要思想是直接从文档级别的注意力选择答案,而不是计算文档的混合特征。
Contextual Embedding
首先将单词转换为one-hot表示,然后利用一个共享embedding matrix We将单词转换为向量表示(与使用word2vec类似)。利用双向GRUs分别获得文档和查询单词的文法表示,每个单词的表示由GRU前向和后向表示连接而成。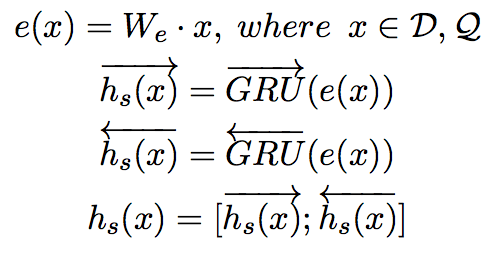
Pair-wise Matching Score
计算每个文档单词与查询单词的匹配值,直接求dot product。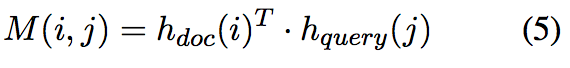
Individual Attentions
通过Pair-wise Matching获得了匹配矩阵M,在矩阵列上使用softmax函数获得每一列的注意力权重,则每一列的结果表示给定一个query单词,仅document-level的注意力。α(t)表示给定t时刻的query单词时document-level的注意力分布,可以认为是query-to-document注意力。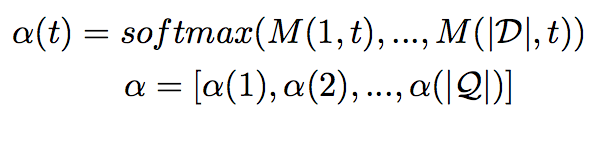
Attention-over-Attention
首先,计算给定一个document单词时query单词的注意力分布,β(t)表示给定t时刻document单词时query-level注意力分布。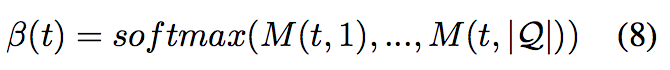
通过上面的计算获得了query-to-document注意力α和document-to-query注意力β。下面对query-level的注意力求均值: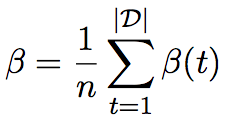
最后计算α与β dot product的结果,作为“attended document-level注意力”。这里的计算表示在t时刻给定query word时对每个仅document-level注意力进行加权求和。每个query word的贡献值可以被显式的学习,最后document-level的注意力经过每个query word的重要性加权获得。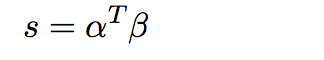
Final Predictions
与《Text understanding with the attention sum reader network》一文类似,本文也采用了sum attention机制获得答案。最终的输出应该被映射到词汇空间V,而非document-level attention |D|,这个对结果影响很大。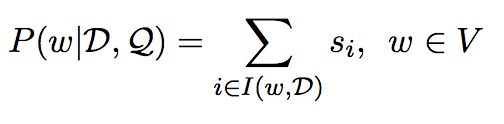
I(w, D)表示单词w在document D中出现的位置。训练时目标函数最大化正确答案的log-likelihood。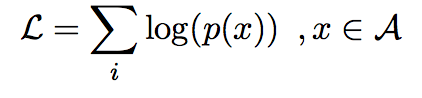
N-best Re-ranking Strategy
一般来说,做完形填空时,都会将候选答案填到句子中,二次检查其是否适合、流畅和符合语法。本文提出了N-best re-ranking策略来进行二次检查。模型输出N个可能性最大的候选答案,然后将这些答案一一填充到句子中,然后对句子进行打分。此种Re-ranking的方法适用于完形填空型阅读理解任务。
Feature Scoring
使用了三种特征:
- Global N-gram LM. 利用训练集中的document数据训练语言模型,计算句子的流畅度。
- Local N-gram LM. 利用测试集中的document数据训练语言模型,计算句子的流畅度。sample-by-sample训练方式,不是在整个测试集上训练,该模型在测试sample中有许多未知词时比较有用。
- Word-class LM. 与global相似,该模型在整个训练集的document数据上进行训练,词转换为对应的词类编号,编号通过聚类方法(mkcls tool)获得。
Experiments
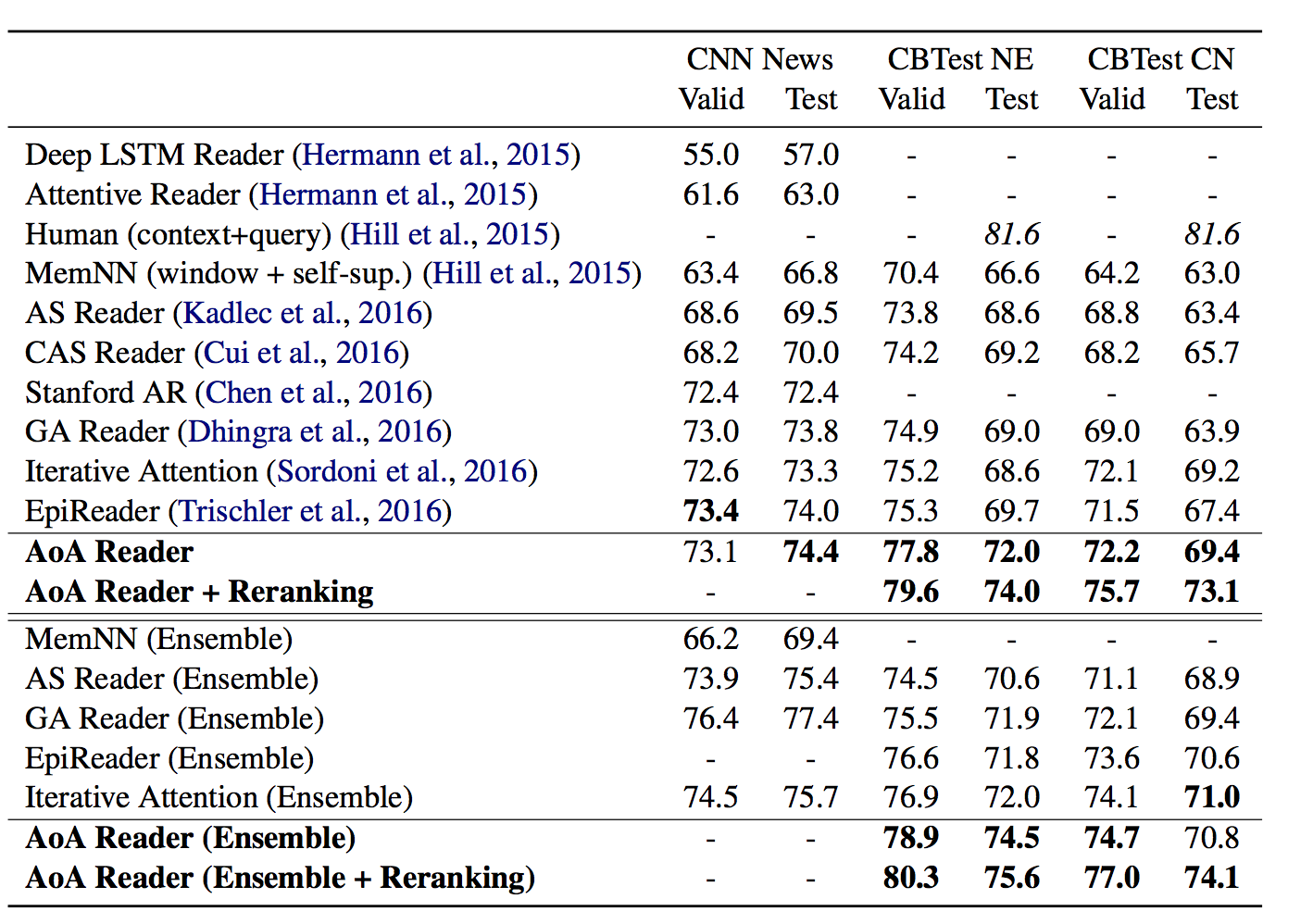
在CNNnews,CBTest NE 和 CN数据集上进行了测试,达到了state-of-art水平。