摘要生成主要有extractive和abstractive两种方式,抽取式直接从原文中抽取整个句子进行组合,生成摘要。而抽象式则类似人类书写摘要的方式,可产生文中不存在的词语。抽取式更为简单,并且在语法和准确性方面可以保证基本的效果。但如果希望拥有神奇的能力,例如 “paraphrasing, generalization, or the incorporation of real-world knowledge”,就需要抽象式模型了。本文的工作对2016年提出的copyNet进行了许多改进,关于copyNet的介绍可以参考:
copyNet在解码阶段会出现多次重复的情况,Pointer-Generator Networks使用Coverage mechanism来解决这个问题,下面具体介绍模型实现细节。
Sequence-to-sequence attentional model
文中首先使用Seq2Seq模型,并结合Attention实现了baseline model,如下图所示: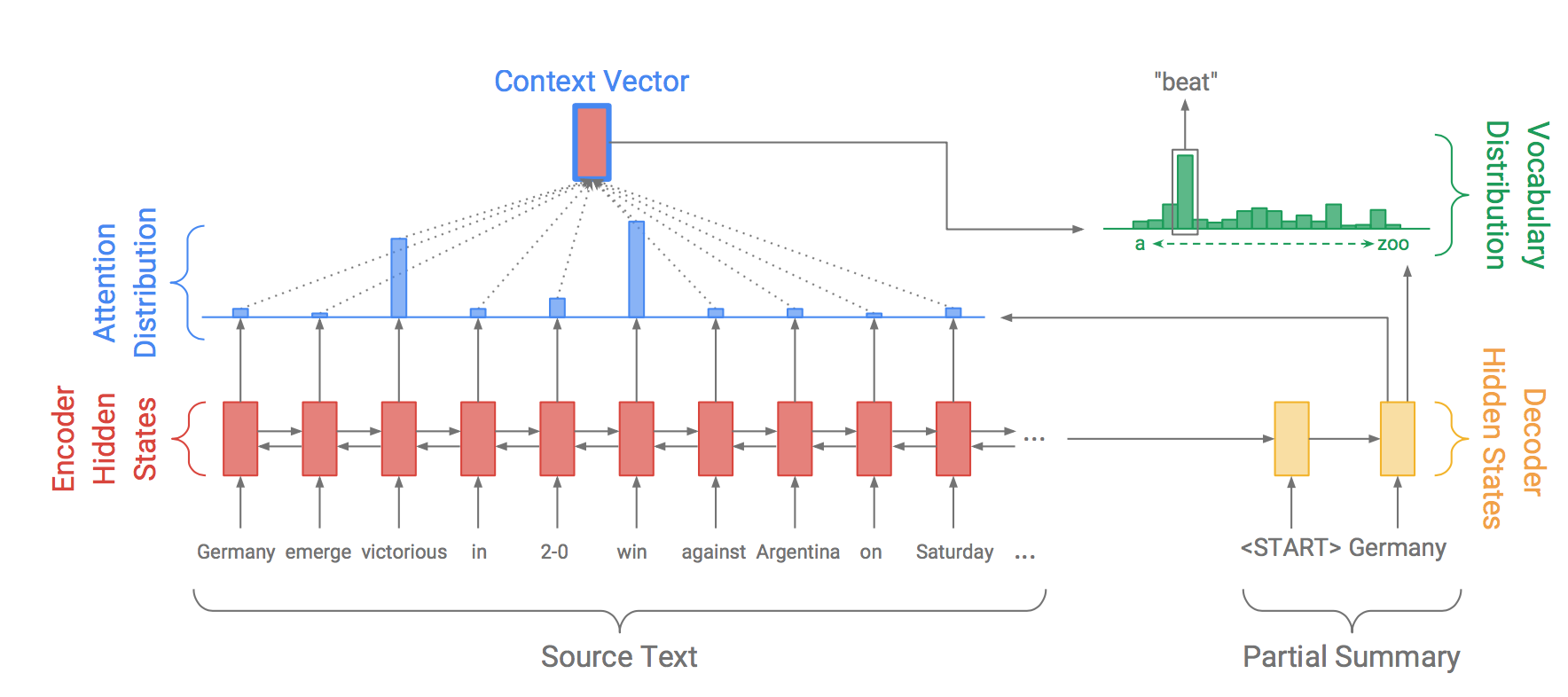
文中提到其attention分布计算方式与Bahdanau[1]在机器翻译中的公式类似,这里补充说明一下,attention机制在NLP领域首次应用正是Bahdanau等人的工作。本文公式如下: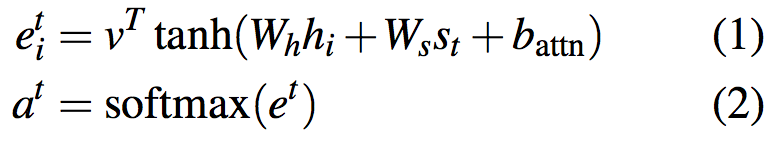
其中$h_t$表示encoder hidden states,$s_t$表示decoder state。v,$W_h$,$W_s$和$b_{attn}$均为可学习的参数。
但本文并未说明$s_t$的计算方式,如果按照Bahdanau一文中的计算方式,貌似有些问题。不妨回顾一下: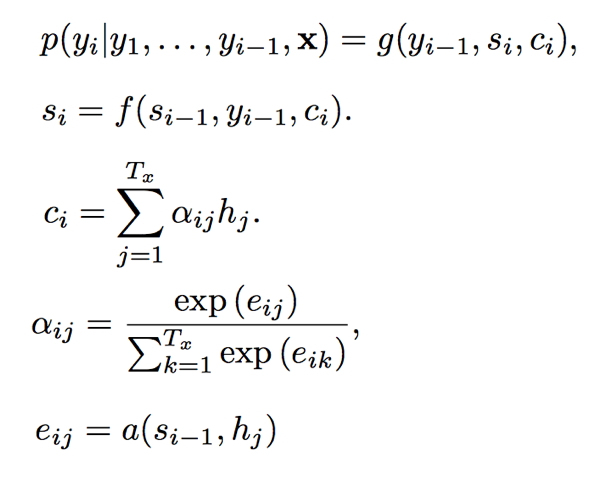
这里暂时偷个懒,公式中的符号就不一一介绍了,可以对比本文的表示方法,基本类似。可以看到,Bahdanau一文中先计算$c_{i}$,然后利用$c_{i}$,$y_{i-1}$和$s_{i-1}$来计算$s_{i}$。而本文在计算context vectors时已经使用了$s_{t}$。而如果本文$s_{t}$计算方式与Bahdanau一文中一致的话,不免有一些矛盾。而公式1中如果是$s_{t-1}$的话就一致了,此处存疑。
Attention distribution表示的是源句子单词的权值分布,用于在解码时有侧重的产生下一个单词。下一步,利用attention distribution产生context vector :
vocab概率分布$P_{vocab}$由context vector和decoder state $s_t$拼接后产生: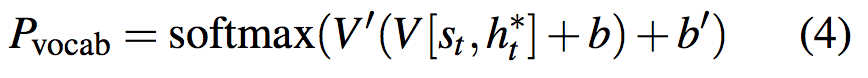
其中V, V’, b和b’是可学习的参数。$P_{vocab}$是词表中所有词的概率分布,而预测词语w的概率为:
$$\begin{gather*}
p\left(w\right) =P_{vocab}\left(w\right)
\end{gather*}$$
训练过程中,每一个时间t的loss由目标word $W^{\ast }_{t}$的negative log likelihood计算得出:
$$\begin{gather*}
loss_{t}=-\log P\left( w^{*}_{t}\right)
\end{gather*}$$
所有输入序列的总loss为:
$$\begin{gather*}
loss=\dfrac {1}{T}\Sigma ^{T}_{t=0}loss_{t}
\end{gather*}$$
Pointer-generator network
Pointer-generator network可以看作baseline model与pointer network[2]的结合。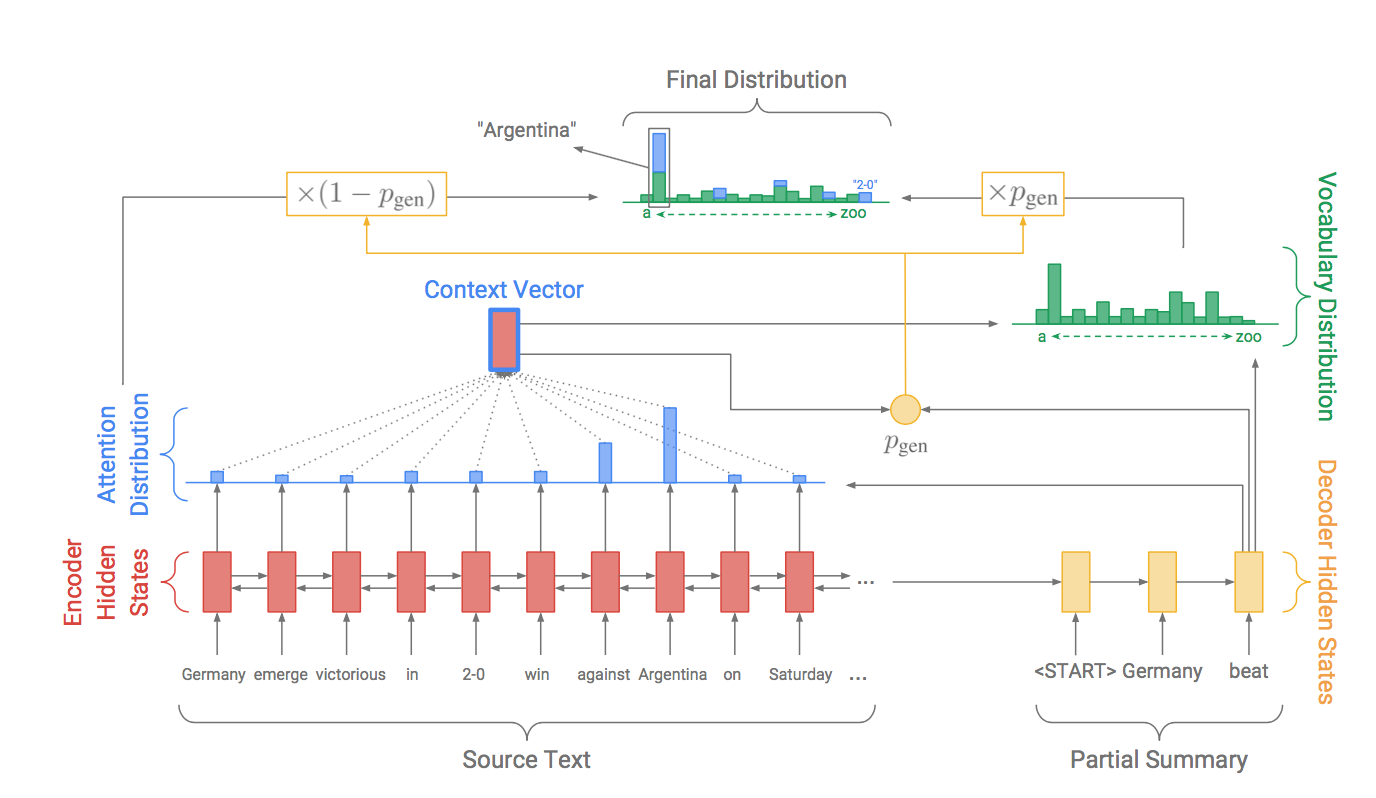
decoder阶段可以利用pointer从源文本copy,也可以从一个固定的词表中生成。模型在每个时间t计算生成概率$p_{gen}$,公式如下: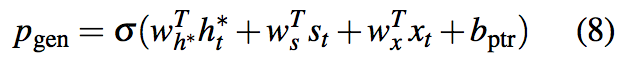
公式中各参数说明参考上文符号,其中$x_{t}$表示decoder输入,$b_{ptr}$表示可学习参数。在生成词语时,$p_{gen}$作为soft switch选择是根据$P_{vocab}$从词表中抽取,还是根据注意力分布$a^t$从输入序列中抽取。两个词表构成extended vocabulary,生成单词时的联合概率计算公式为: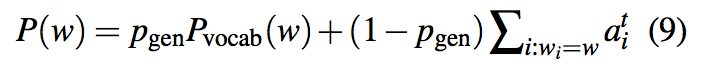
如果w是一个out-of-vocabulary (OOV)单词,则$P_{vocab}(w)$=0;同理,如果w在输入文档中没有出现,那么$\Sigma _{i:w_{i}=w}a^{t}_{i}$=0。Pointer-generator模型的主要优势就是可以产生OOV单词。
Coverage mechanism
Sequence-to-sequence模型在生成句子或摘要时普遍存在重复的问题,在关于copy-net介绍中也提到了这一点。该模型利用coverage mechanism来解决重复的问题,保留一个coverage vector $c^t$,由所有之前decoder时间步的注意力分布相加获得,计算公式如下:
直观看来,$c^t$代表了源文档中各个词语截至目前由attention mechanism所决定的“受关注程度”。Coverage vector作为一个额外的信息输入attention mechanism,则公式(1)变为: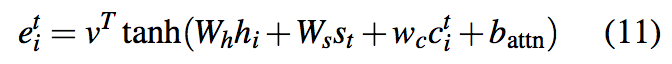
$w_c$是一个可学习参数,这使attention mechanism当前决策受到之前决策$c^t$的影响,从而使attention mechanism不总是关注一个位置,避免产生重复的文本。
loss函数方面,该文定义了coverage loss来对重复关注同样的位置进行惩罚: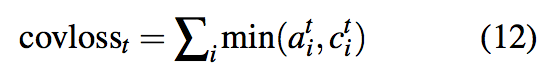
coverage loss是有界的,$covloss_{t}\leq \sum _{i}a^{i}_{t}=1$。最终,coverage loss通过一个超参数$\lambda$来进行权衡,与原来的loss函数组合为新的loss函数: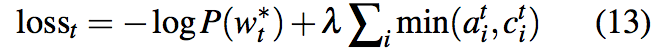
直观上,可以这样理解。模型希望从loss角度对持续受到关注的位置进行惩罚,如果当前时刻某个位置受到的关注很多,不妨假设$a^{t}_{i}>c^{t}_{i}$,那么就要对其进行惩罚,惩罚程度为其累计收到的关注度,惩罚较大。而如果当前时刻某个位置受到的关注很少,不妨假设$a^{t}_{i}<c^{t}_{i}$,那么就对其进行较小的惩罚,取不妨假设$a^{t}_{i}$。通过超参数$\lambda$来调和两方面的loss。
源码
github地址:
由于Tensorflow升级,使部分代码需要更新,可以参考本人修改后的分支:
引用
[1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben- gio. 2015. Neural machine translation by jointly learning to align and translate. In International Con- ference on Learning Representations.
[2] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer networks. In Neural Information Pro- cessing Systems.