TextRank算法可以用于提取文本关键词和生成摘要,其思想来源于PageRank算法。Google的两位创始人在斯坦福大学读研期间从事网页排序研究时,受到学术界对学术论文重要性的评估方法(论文引用次数)启发,提出了PageRank算法。PageRank算法的核心思想比较直观:
- 如果一个网页被很多其他网页链接到,说明这个网页很重要,对应的PR(PageRank)值也越高;
- 如果一个PR值较高的网页链接了某个网页,则该网页的PR值也会相应提高。
算法原理
PageRank
将网页之间的链接抽象为一张有向图,如下图所示: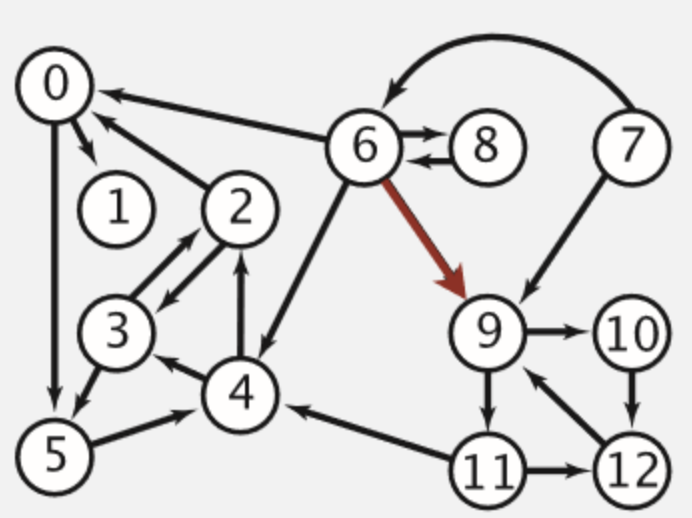
图结构构造完成后,可使用以下公式计算网页的PR值:
$$\begin{gather*} S\left(V_{i}\right)=(1-d)+d * \sum_{j \in I n\left(V_{i}\right)} \frac{1}{\left|O u t\left(V_{j}\right)\right|} S\left(V_{j}\right) \end{gather*}$$
$S\left(V_{i}\right)$表示网页i的PR值,即网页的重要性指标。d是阻尼系数,一般取0.85。$I n\left(V_{i}\right)$表示指向网页i的网页集合。$|O u t\left(V_{j}\right)|$表示网页j指向的网页总数,$S\left(V_{j}\right)$表示网页j的PR值。可将各网页PR值设置为1,经过多次迭代,满足收敛条件后获得各个网页的PR值。
阻尼系数:
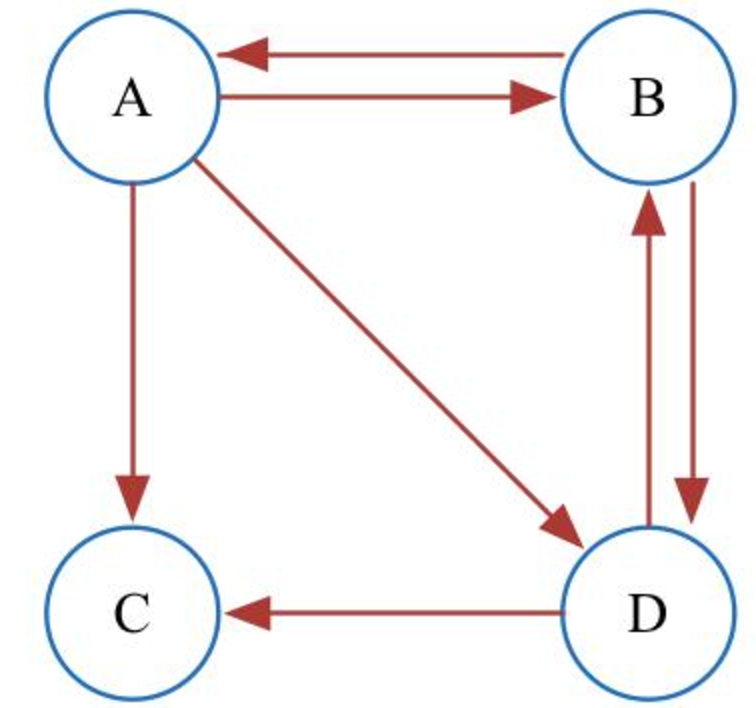
PageRank算法可以视为对网页跳转的模拟,当有些网页只有入链而没有出链时,则无法从这些网页跳转出去,使得每个网页的PageRank值最终为0。下图给出了这个问题的实例,网页C没有到其他页面的链接,随着算法的不断迭代,每个网页的权重值不断减少,最终收敛于0。为了避免这个问题,在算法中引入阻尼系数d,作为网页随机跳转的概率。
TextRank
关键词提取
以下面的文章为例,首先进行过滤停用词等预处理(中文需要分词),然后建立如图所示单词之间的连接图,此时PageRank算法中网页之间的链接关系体现为一定窗口大小内单词之间的相邻关系,例如以“systems”为中心,窗口大小为3时,”types”, “linear”和“compatibility”与其具有“链接关系“。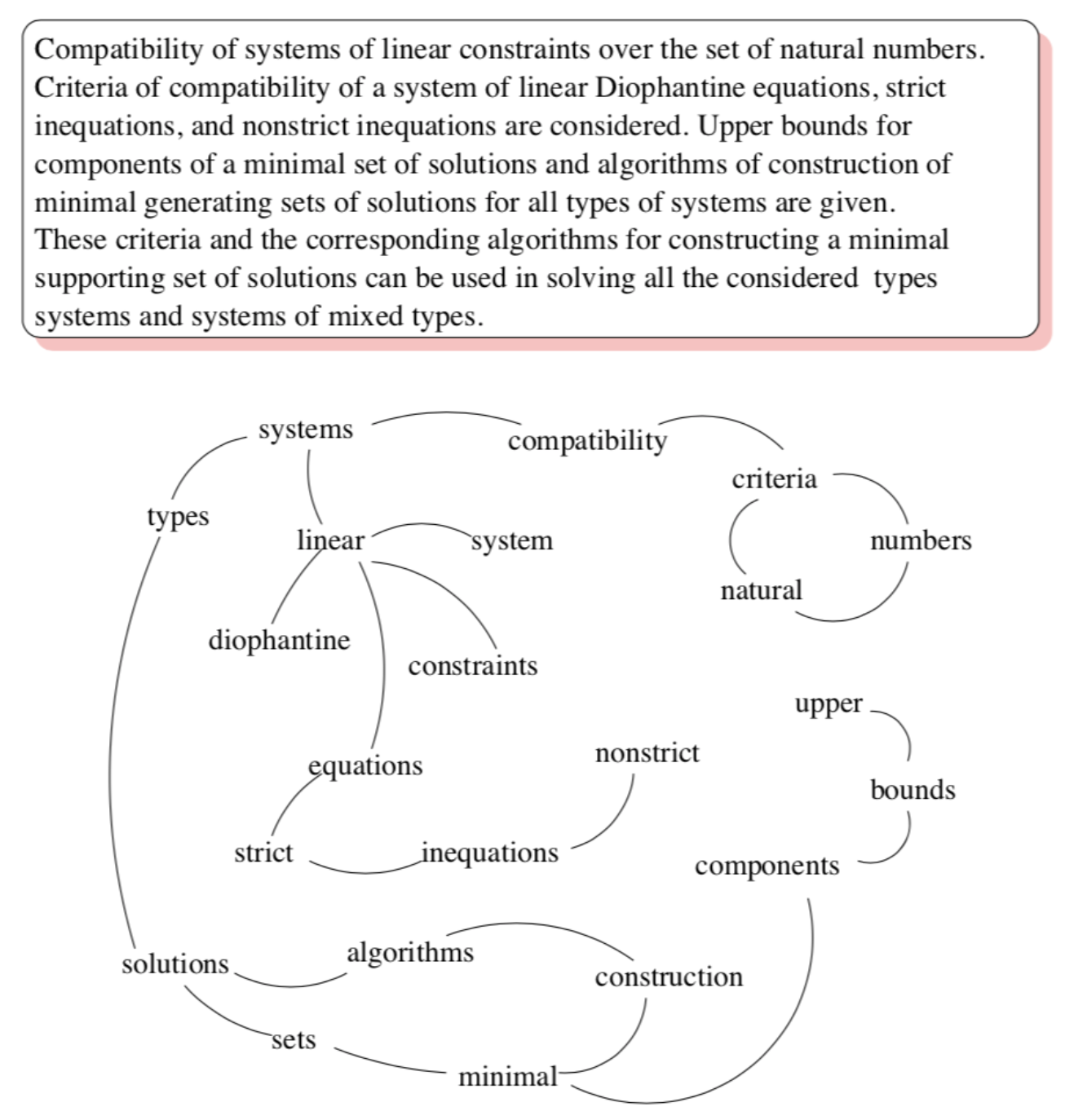
图构造完成后,单词的TR值计算公式为:
$$\begin{gather*} W S\left(V_{i}\right)=(1-d)+d * \sum_{V_{j} \in I n\left(V_{i}\right)} \frac{w_{j i}}{\sum_{V_{k} \in O u t\left(V_{j}\right)} w_{j k}} W S\left(V_{j}\right) \end{gather*}$$
TR值计算公式与PR值十分类似,区别在于加入了一个参数$w_{j i}$,一般来说$w_{j i}$的值为文章中第j个单词和第i个单词在一定窗口大小的共现次数。后续的迭代过程与PR值计算类似。
摘要生成
将文本中的每个句子看作图中的一个节点,句子之间的“链接关系”由句子间的相似性体现。句子相似性有多种计算方式,这里使用一种很简单的方法,计算两个句子共有词比例。句子相似性公式:
$$\begin{gather*}
\text {Similarity}\left(S_{i}, S_{j}\right)=\frac{\left|\left\{w_{k} | w_{k} \in S_{i} \& w_{k} \in S_{j}\right\}\right|}{\log \left(\left|S_{i}\right|\right)+\log \left(\left|S_{j}\right|\right)}
\end{gather*}$$
$S_{i}, S_{j}$分别表示第i个和第j个句子,$w_{k}$表示句子中的词语,公式中分子表示两个句子共有词的个数,分母表示两个句子词总数对数求和。后续TR值计算和迭代过程与关键词提取类似。
参考资料
http://www.cnblogs.com/xueyinzhe/p/7101295.html
https://blog.csdn.net/woshiliulei0/article/details/81479434
本文中图片均来自互联网