BERT除预训练代码run_pretraining.py外,还提供了run_classifier.py用于文本分类和run_squad.py用于阅读理解,下面通过对比三个代码总结出如何快速基于BERT做二阶段fine tune的方法。此外,如果TF Hub中有对应任务可使用的预训练模型,也可直接使用,例如同样用于分类的run_classifier_with_tfhub.py。
代码整体结构
代码的整体流程如下图所示: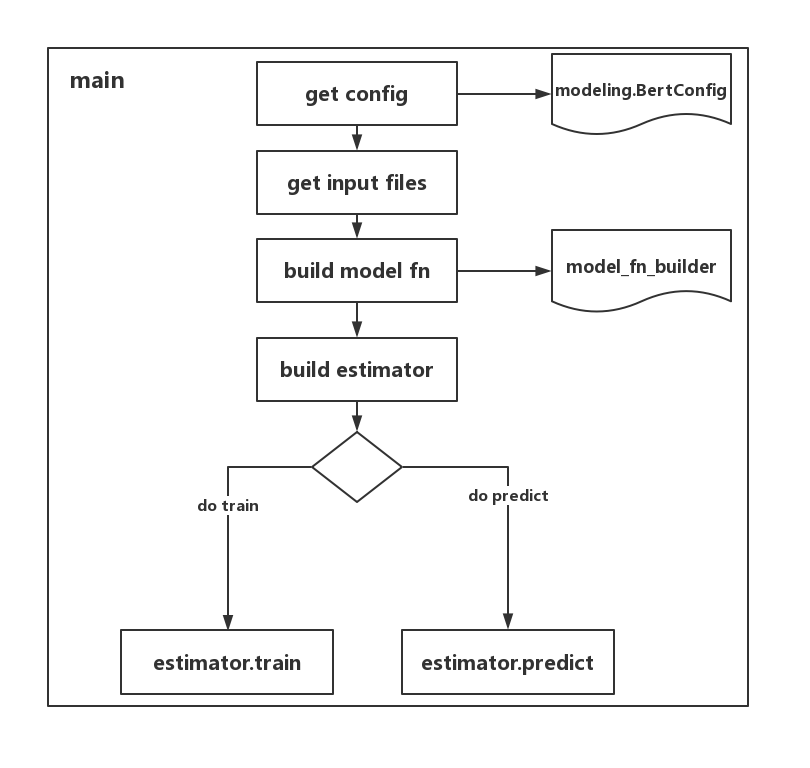
配置
在bert_config_file文件中配置各个参数,例如attention_probs_dropout_prob和directionality等,config文件在BERT提供的预训练模型中。
输入处理
结构图中以get input files表示整个的输入数据处理部分,不同于早期版本的数据处理过程,当前的TF版本将数据转化为features用于训练。所以需要建立相应的结构体承接数据,并建立对应的数据处理方法,最后转化为features,下表中convert_exps_to_features为convert_examples_to_features简写。
| 代码/功能 | 承接数据 | 数据处理方法 | 转化为features |
|---|---|---|---|
| run_classifier.py | InputExample, InputFeatures | DataProcessor | convert_single_example |
| run_squad.py | SquadExample, InputFeatures | read_squad_examples | convert_exps_to_features |
建立模型
以run_classifier.py为例,使用model_fn_builder函数建立模型。
具体地,将配置、训练数据等信息传入create_model函数。
create_model函数首先基于BERT建立模型。
然后根据需要取得BERT模型的输出,例如在run_classifier.py中:
run_squad.py中:
此部分相当于利用BERT作为一个Encoder来编码输入信息,随后便可根据任务定义对应的可学习参数和loss。
建立estimator
根据已建立的模型和配置信息新建estimator。
开始训练
使用input_fn_builder建立训练数据,输入estimator开始训练。
使用TF Hub
run_classifier_with_tfhub.py与run_classifier.py整体流程非常类似,区别在于run_classifier_with_tfhub.py中获得BERT模型是通过TF Hub。
获得BERT模型输出时需要指定signature。
其他部分与run_classifier.py类似。
新任务
对于一个新任务,可参考run_classifier.py代码进行修改,主要修改数据处理、模型建立等部分,具体地,InputExample,InputFeatures,convert_examples_to_features和create_model函数等。