
这篇文章希望站着把三件事办了:
- 理解Lambda;
- 理解MART;
- 理解LambdaMART。
Lambda
关于Lambda梯度要从RankNet说起,RankNet提出了一种概率损失函数来学习Ranking Function,并应用Ranking Function对文档进行排序。LambdaRank在RankNet的基础上引入评价指标Z (如NDCG、ERR等),其损失函数的梯度代表了文档下一次迭代优化的方向和强度,由于引入了IR评价指标,Lambda梯度更关注位置靠前的优质文档的排序位置的提升,有效的避免了下调位置靠前优质文档的位置这种情况的发生。LambdaRank相比RankNet的优势在于分解因式后训练速度变快,同时考虑了评价指标,直接对问题求解,效果更明显。 详细内容可以参考搜索排序算法。
MART
MART(Multiple Additive Regression Tree)的另一个名字叫GBDT(Gradient Boosting Decision Tree),理解GBDT要从BT开始。
提升树
BT(Boosting Tree)提升树是以决策树为基本学习器的提升方法,它被认为是统计学习中性能最好的方法之一。对于分类问题,提升树的决策树是二叉决策树,对于回归问题,提升树中的决策是二叉回归树。
提升树模型可以表示为决策树为基学习器的加法模型:
$$\begin{gather*} f(\overrightarrow{\mathbf{x}})=f_{M}(\overrightarrow{\mathbf{x}})=\sum_{m=1}^{M} h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right) \end{gather*}$$其中$h_{m}\left(\overrightarrow{\mathbf{x}} \Theta_{m}\right)$表示第m个决策树,$\Theta_{m}$为第m个决策树的参数,M为决策树的数量。
提升树采用前向分步算法:
- 首先确定初始提升树$f_{0}(\overrightarrow{\mathbf{x}})=0$。
- 第m步模型为:$f_{m}(\overrightarrow{\mathbf{x}})=f_{m-1}(\overrightarrow{\mathbf{x}})+h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right)$,其中$h_{m}(\cdot)$为待求的第m棵决策树。
- 通过经验风险极小化确定第m棵决策树的参数$\Theta_{m}: \hat{\Theta}_{m}=\arg \min _{\Theta_{m}} \sum_{i=1}^{N} L\left(\bar{y}_{i}, f_{m}\left(\overrightarrow{\mathbf{x}}_{i}\right)\right)$。这里没有引入正则项,而XGBoost中引入了正则项。
不同问题的提升树学习算法主要区别在于使用的损失函数不同,(设预测值为$\tilde{y}$ ,真实值为$\hat{y}$):
- 回归问题:通常使用平方误差损失函数$L(\tilde{y}, \hat{y})=(\tilde{y}-\hat{y})^{2}$。
- 分类问题:通常使用指数损失函数:$L(\tilde{y}, \hat{y})=e^{-\tilde{y} \hat{y}}$
提升树的学习思想有点类似一打高尔夫球,先粗略的打一杆,然后在之前的基础上逐步靠近球洞,也就是说每一棵树学习的是之前所有树预测值和的残差,这个残差就是一个加预测值后得到真实值的累加量。
例如在回归问题中,提升树采用平方误差损失函数,此时:
$$\begin{gather*} \begin{aligned} L\left(\tilde{y}, f_{m}(\overrightarrow{\mathbf{x}})\right) &=L\left(\tilde{y}, f_{m-1}(\overrightarrow{\mathbf{x}})+h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right)\right) =\left(\tilde{y}-f_{m-1}(\overrightarrow{\mathbf{x}})-h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right)\right)^{2} &=\left(r-h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right)\right)^{2} \end{aligned} \end{gather*}$$其中$r=\tilde{y}-f_{m-1}(\overrightarrow{\mathbf{x}})$为当前模型拟合数据的残差。所以对回归问题的提升树算法,第m个决策树 $h_{m}(\cdot)$只需要简单拟合当前模型的残差。
回归提升树算法如下:

梯度提升树(GBT)
上面所讲的提升树中,当损失函数是平方损失函数和指数损失函数时,每一步优化都很简单。因为平方损失函数和指数损失函数的求导非常简单。当损失函数是一般函数时,往往每一步优化不是很容易。针对这个问题,Freidman提出了梯度提升树算法(GBT)。
梯度提升树(GBT)的一个核心思想是利用损失函数的负梯度在当前模型的值作为残差的近似值,本质上是对损失函数进行一阶泰勒展开,从而拟合一个回归树。
如何理解用负梯度近似残差
在对目标函数进行优化时,负梯度往往是函数下降最快的方向,自然也是GBDT目标函数下降最快的方向,所以用梯度去拟合首先是没什么问题的(并不是拟合梯度,只是用梯度去拟合);GBDT本来中的g代表gradient,本来就是用梯度拟合;
用残差去拟合,只是目标函数是均方误差的一种特殊情况,CART中采用均方误差,符合这种情况。
为什么不直接使用残差拟合?目标函数除了loss可能还有正则项,正则中有参数和变量,很多情况下只拟合残差loss变小但是正则变大,目标函数不一定就小,这时候就要用梯度了,梯度的本质也是一种方向导数,综合了各个方向(参数)的变化,选择了一个总是最优(下降最快)的方向;
泰勒展开公式:
$$\begin{gather*}
TaylorExpansion:f(x+\Delta x) \simeq f(x)+f^{\prime}(x) \Delta x+\frac{1}{2} f^{\prime \prime}(x) \Delta x^{2}
\end{gather*}$$
将损失函数使用一阶泰勒展开公式($\Delta x$相当于这里的$h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right))$:
则有:
$$\begin{gather*} \Delta L=L\left(\tilde{y}, f_{m}(\overrightarrow{\mathbf{x}})\right)-L\left(\tilde{y}, f_{m-1}(\overrightarrow{\mathbf{x}})\right)=\frac{\partial L\left(\tilde{y}, f_{m-1}(\overrightarrow{\mathbf{x}})\right)}{\partial f_{m-1}(\overrightarrow{\mathbf{x}})} h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right) \end{gather*}$$要使得损失函数降低,则根据梯度下降的思想让损失函数对$h_{m}\left(\overrightarrow{\mathbf{x}} ; \mathbf{\Theta}_{m}\right)$进行求导,按照负梯度更新该值,则损失函数是下降的,即:$h_{m}\left(\overrightarrow{\mathbf{x}} ; \Theta_{m}\right)=-\frac{\partial L\left(\tilde{y}, f_{m-1}(\overrightarrow{\mathbf{x}})\right)}{\partial f_{m-1}(\overrightarrow{\mathbf{x}})}$
这里进一步解释一下,对于函数f:
$$\begin{gather*}
f\left(\theta_{k+1}\right) \approx f\left(\theta_{k}\right)+\frac{\partial f\left(\theta_{k}\right)}{\partial \theta_{k}}\left(\theta_{k+1}-\theta_{k}\right)
\end{gather*}$$
使用梯度下降算法时,$\theta_{k+1}=\theta_{k+1}-\eta \frac{\partial f\left(\theta_{k}\right)}{\partial \theta_{k}}$。
而在GBDT中,我们对损失函数进行展开:$L\left(y, f_{m}(x)\right) \approx L\left(y, f_{m-1}(x)\right)+\frac{\partial L\left(y, f_{m-1}(x)\right)}{\partial f_{m-1}(x)}\left(f_{m}(x)-f_{m-1}(x)\right)$
即,$L\left(y, f_{m}(x)\right) \approx L\left(y, f{m-1}(x)\right)+\frac{\partial L\left(y, f_{m-1}(x)\right)}{\partial f_{m-1}(x)} T_{m}(x)$
在优化$L(y, f(x))$时,应用梯度下降算法时,有:$f_{m}(x)=f_{m-1}(x)-\eta \frac{\partial L\left(y, f_{m-1}(x)\right)}{\partial f_{m-1}(x)}$
则有$T_{m}(x)=-\eta \frac{\partial L\left(y, f{m-1}(x)\right)}{\partial f_{m-1}(x)}$ ,即负梯度可以近似认为是残差,区别在于$\eta$。
- 对于平方损失函数,它就是通常意义的残差。
- 对于一般损失函数,它就是残差的近似。
这里我们相当于获得了样本的标签,接下来就是用这个标签来训练决策树。
另外,梯度提升树用于分类模型时,是梯度提升决策树GBDT;用于回归模型时,是梯度提升回归树GBRT,二者的区别主要是损失函数不同。
GBRT算法的伪代码如下:

另外,Freidman从bagging策略受到启发,采用随机梯度提升来修改了原始的梯度提升算法,即每一轮迭代中,新的决策树拟合的是原始训练集的一个子集(而并不是原始训练集)的残差,这个子集是通过对原始训练集的无放回随机采样而来,类似于自助采样法。这种方法引入了随机性,有助于改善过拟合,另一个好处是未被采样的另一部分子集可以用来计算包外估计误差。
这时我们再看一下LambdaMART算法的流程:

对比GBRT和LambdaMART算法流程可以发现两者非常相似,主要区别是LambdaMART将GBRT中要拟合的负梯度替换为Lambda梯度,而LambdaMART对排序的最核心的改进正是这个Lambda梯度,具体介绍可以参考搜索排序算法)中关于RankNet和LambdaRank的介绍。
XGBoost
这里既然提到了提升树和梯度提升树,那么顺便也介绍一下大名鼎鼎的XGBoost,这部分介绍完后我们再探LambdaMART的一些细节。
Xgboost也使用与提升树相同的前向分步算法,其区别在于:Xgboost通过结构风险最小化来确定下一个决策树的参数$\Theta_{m}$:
$\hat{\Theta}_{m}=\arg \min _{\Theta_{m}} \sum_{i=1}^{N} L\left(\tilde{y}_{i}, f_{m}\left(\overrightarrow{\mathbf{x}}_{i}\right)\right)+\Omega\left(h_{m}(\overrightarrow{\mathbf{x}})\right)$其中:
- $\Omega\left(h_{m}\right)$为第m个决策树的正则化项,这是XGBoost和GBT的一个重要区别。
- $\mathcal{L}=\sum_{i=1}^{N} L\left(\tilde{y}_{i}, f_{m}\left(\overrightarrow{\mathbf{x}}_{i}\right)\right)+\Omega\left(h_{m}(\overrightarrow{\mathbf{x}})\right)$为目标函数。
与提升树不同的是,Xgboost还使用了二阶泰勒展开,定义:
$\hat{y}_{i}^{<m-1>}=f_{m-1}\left(\overrightarrow{\mathbf{x}}_{i}\right), \quad g_{i}=\frac{\partial L\left(\tilde{y}_{i}, \hat{y}_{i}^{<m-1>}\right)}{\partial \hat{y}_{i}^{<m-1>}}, \quad h_{i}=\frac{\partial^{2} L\left(\tilde{y}_{i}, \hat{y}_{i}^{<m-1>}\right)}{\partial^{2} \hat{y}_{i}^{<m-1>}}$其中,$g_{i}, h_{i}$分别是损失函数$L\left(\tilde{y}_{i}, \hat{y}_{i}^{<m-1>}\right)$对$\hat{y}_{i}^{<m-1>}$的一阶导数和二阶导数。再看泰勒展开式:
Taylor expansion $f(x+\Delta x) \simeq f(x)+f^{\prime}(x) \Delta x+\frac{1}{2} f^{\prime \prime}(x) \Delta x^{2}$
因此我们对损失函数二阶泰勒展开有($\Delta x$相当于这里的$h_{m}(\overrightarrow{\mathbf{x}})$)
$$\begin{gather*} \begin{aligned} \mathcal{L} &=\sum_{i=1}^{N} L\left(\tilde{y}_{i}, f_{m}\left(\overrightarrow{\mathbf{x}}_{i}\right)\right)+\Omega\left(h_{m}(\overrightarrow{\mathbf{x}})\right)=\sum_{i=1}^{N} L\left(\tilde{y}_{i}, \hat{y}_{i}^{<m-1>}+h_{m}\left(\overrightarrow{\mathbf{x}}_{i}\right)\right)+\Omega\left(h_{m}(\overrightarrow{\mathbf{x}})\right) \\ & \simeq \sum_{i=1}^{N}\left[L\left(\tilde{y}_{i}, \hat{y}_{i}^{<m-1>}\right)+g_{i} h_{m}\left(\overrightarrow{\mathbf{x}}_{i}\right)+\frac{1}{2} h_{i} h_{m}^{2}\left(\overrightarrow{\mathbf{x}}_{i}\right)\right]+\Omega\left(h_{m}(\overrightarrow{\mathbf{x}})\right)+\text { constant } \end{aligned} \end{gather*}$$提升树(GBT)只使用了一阶泰勒展开。而XGBoost的正则化项由两部分组成:$\Omega\left(h_{m}(\overrightarrow{\mathbf{x}})\right)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}$
该部分表示决策树的复杂度,其中T为叶节点的个数,$w_{j}$为每个叶节点的输出值,$\gamma, \lambda \geq 0$为系数,控制这两个部分的比重。
- 叶结点越多,则决策树越复杂。
- 每个叶结点输出值的绝对值越大,则决策树越复杂。
该复杂度是一个经验公式。事实上还有很多其他的定义复杂度的方式,只是这个公式效果还不错。
Xgboost相比与GBDT:
传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。例如,xgboost支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)
xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样(即每次的输入特征不是全部特征),不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
并行化处理:在训练之前,预先对每个特征内部进行了排序找出候选切割点,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行,即在不同的特征属性上采用多线程并行方式寻找最佳分割点。
相比于GBDT,Xgboost最重要的优点还是用到了二阶泰勒展开信息和加入正则项 。
LambdaMART
LambdaMART算法的流程:
叶子结点输出值的计算采用牛顿迭代法,对于一个函数$g(\gamma)$,为了找到$\gamma$使得函数$g$取得极小(大)值采用牛顿迭代法的迭代步骤为:
$$\begin{gather*} \gamma_{n+1}=\gamma_{n}-\frac{g^{\prime}\left(\gamma_{n}\right)}{g^{\prime \prime}\left(\gamma_{n}\right)} \end{gather*}$$相应地,LambdaMART第m棵树中第k个叶子结点的输出值计算公式为:
$$\begin{gather*} \gamma_{k m}=\frac{\sum_{x_{i} \in R_{k m}} \frac{\partial C}{\partial s_{i}}}{\sum_{x_{i} \in R_{k m}} \frac{\partial^{2} C}{\partial s_{i}^{2}}}=\frac{-\sum_{x_{i} \in R_{k m}} \sum_{\{i, j\} \rightleftharpoons I}\left|\Delta Z_{i j}\right| \rho_{i j}}{\sum_{x_{i} \in R_{k m}} \sum_{\{i, j\} \rightleftharpoons I}\left|\Delta Z_{i j}\right| \sigma \rho_{i j}\left(1-\rho_{i j}\right)} \end{gather*}$$具体原理可以参考From RankNet to LambdaRank to LambdaMART: An Overview
下面我们基于Ranklib源码和一个具体的例子来进一步理解LambdaMART算法的过程。Ranklib是Learning to Rank领域的一个优秀的开源算法库,实现了MART,RankNet,RankBoost,LambdaMart,Random Forest等模型,代码为Java。我们这里基于微软发布的LambdaMART来进行介绍,LambdaMART.java中的LambdaMART.learn()是学习流程的管控函数,学习过程主要有下面四步构成:
计算deltaNDCG以及lambda;
以lambda作为label训练一棵regression tree;
在tree的每个叶子节点通过预测的regression lambda值还原出gamma,即最终输出得分;
用3的模型预测所有训练集合上的得分(+learningRate*gamma),然后用这个得分对每个query的结果排序,计算新的每个query的base ndcg,以此为基础回到第1步,组成森林。
重复这个步骤,直到满足下列两个收敛条件之一:
树的个数达到训练参数设置;
Random Forest在validation集合上没有变好。
下面用一组实际的数据来说明整个计算过程,假设我们有10个query的训练数据,每个query下有10个doc,每个query-doc对有10个feature,如下:
|
|
为了简便,省略了余下的数据。上面的数据格式是按照Ranklib readme中要求的格式组织,除了行号之外,第一列是query-doc对的实际label(人工标注数据),第二列是qid,后面10列都是feature。
这份数据每组qid中的doc初始顺序可以是随机的,也可以是从实际的系统中获得的顺序,总之这个是计算ndcg的初始状态。对于qid=1830,它的10个doc的初始顺序的label序列是:0, 0, 0, 1, 1, 0, 1, 1, 0, 0(实际中label可以扩展为1,2,3,4等,根据数据自行决定)。dcg的计算公式为:
$$\begin{gather*} dcg(i)=\frac{2^{l a b e l(i)}-1}{\log _{2}(i+1)} \end{gather*}$$i表示当前doc在这个qid下的位置(从1开始,避免分母为0),label(i)是doc(i)的标注值。而一个query的dcg则是其下所有doc的加和:
$$\begin{gather*} dcg(query)=\sum_{i} \frac{2^{l a b e l(i)}-1}{\log _{2}(i+1)} \end{gather*}$$根据上式可以计算初始状态下每个qid的dcg:
$$\begin{gather*} \begin{aligned} d c g(q i d=1830) &=\frac{2^{0}-1}{\log _{2}(1+1)}+\frac{2^{0}-1}{\log _{2}(2+1)}+\ldots+\frac{2^{0}-1}{\log _{2}(10+1)} \\ &=0+0+0+0.431+0.387+0+0.333+0.315+0 \\ &+0=1.466 \end{aligned} \end{gather*}$$要计算ndcg,还需要计算理想集的dcg,将初始状态按照label排序,qid=1830得到的序列是1,1,1,1,0,0,0,0,0,0,计算dcg:
$$\begin{gather*} ideal_dcg(qid =1830) =\frac{2^{1}-1}{\log _{2}(1+1)}+\frac{2^{1}-1}{\log _{2}(2+1)}+\ldots \begin{aligned}+\frac{2^{0}-1}{\log _{2}(10+1)} & \\ &=1+0.631+0.5+0.431+0+0+0+0+0+0 \\ &=2.562 \end{aligned} \end{gather*}$$两者相除得到初始状态下qid=1830的ndcg:
$$\begin{gather*} ndcg(qid=1830)=\frac{dcg(qid=1830)}{ideal_{-} ndcg(qid=1830)}=\frac{1.466}{2.562}=0.572 \end{gather*}$$下面要计算每一个doc的deltaNDCG,公式如下:
$$\begin{gather*} \begin{array}{c} \operatorname{deltaNDCG}(i, j) \\ =| \text {ndcg(original sequence) }-ndcg(\operatorname{swap}(i, j) \text { sequence }) | \end{array} \end{gather*}$$deltaNDCG(i,j)是将位置i和位置j的位置互换后产生的ndcg变化(其他位置均不变),显然有相同label的deltaNDCG(i,j)=0。在qid=1830的初始序列0, 0, 0, 1, 1, 0, 1, 1, 0, 0,由于前3的label都一样,所以deltaNDCG(1,2)=deltaNDCG(1,3)=0,不为0的是deltaNDCG(1,4), deltaNDCG(1,5), deltaNDCG(1,7), deltaNDCG(1,8)。将1,4位置互换,序列变为1, 0, 0, 0, 1, 0, 1, 1, 0, 0,计算得到dcg=2.036,整个deltaNDCG(1,4)的计算过程如下:
$$\begin{gather*} \begin{array}{l} \qquad \begin{array}{l} dcg(q i d=1830, \operatorname{swap}(1,4))=\frac{2^{1}-1}{\log _{2}(1+1)}+\frac{2^{0}-1}{\log _{2}(2+1)}+\ldots \\ +\frac{2^{0}-1}{\log _{2}(10+1)} \end{array} \\ =1+0+0+0+0.387+0+0.333+0.315+0+0 \\ =2.036 \end{array} \end{gather*}$$ $$\begin{gather*} \begin{array}{l} n d c g(swap(1,4))=\frac{d c g(swap(1,4))}{ideal_{-} dcg}=\frac{2.036}{2.562}=0.795 \\ \text {deltaNDCG}(1,4)=\operatorname{detal} N D C G(4,1) \\ =| \text {ndcg}(\text {original sequence})-\text {ndcg}(\operatorname{swap}(1,4)) | \\ =|0.572-0.795|=0.222 \end{array} \end{gather*}$$同样过程可以计算出deltaNDCG(1,5)=0.239, deltaNDCG(1,7)=0.260, deltaNDCG(1,8)=0.267等。
进一步,要计算lambda(i),根据paper,还需要ρ值,ρ可以理解为$doc_i$比$doc_j$差的概率,其计算公式为:
$\rho_{i j}=\frac{1}{1+e^{\sigma\left(s_{i}-s_{j}\right)}}$参考搜索排序算法)中关于LambdaRank的介绍:
$$\begin{gather*} \lambda_{i j}=\frac{\partial C\left(s_{i}-s_{j}\right)}{\partial s_{i}}=\frac{-\sigma}{1+e^{\sigma\left(s_{i}-s_{j}\right)}}\left|\Delta_{N D C G}\right| \end{gather*}$$Ranklib中直接取σ=1,如下图,蓝,红,绿三种颜色分别对应σ=1,2,4时ρ函数的曲线情形(横坐标是$s_i-s_j$):
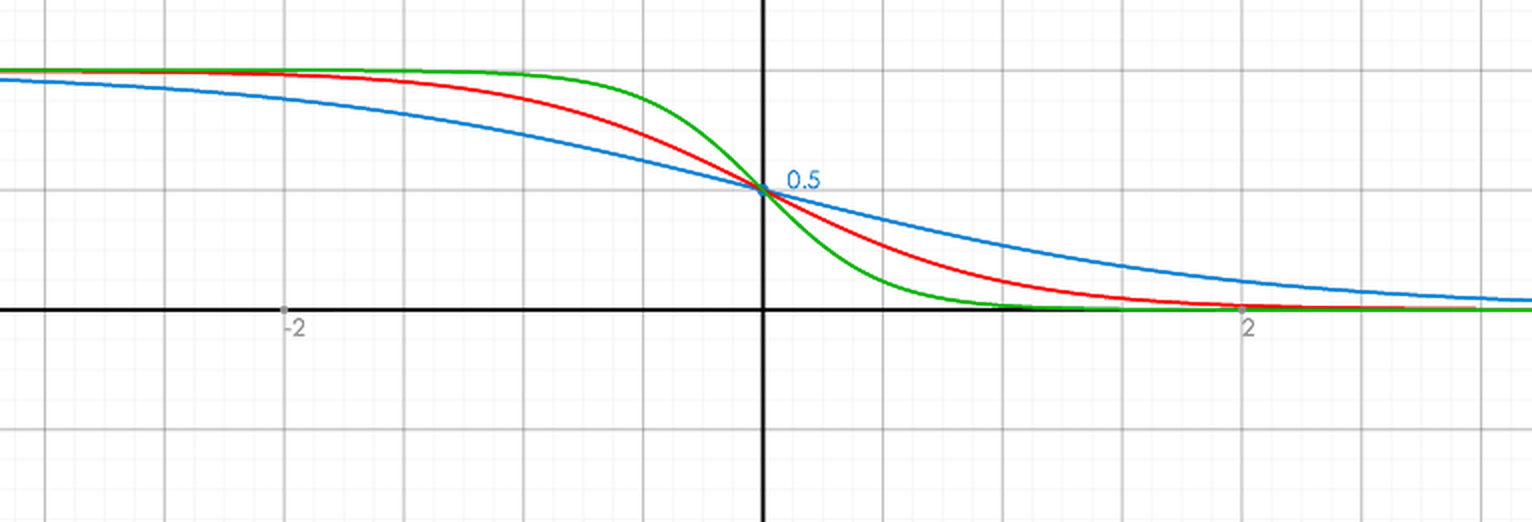
初始时,模型为空,所有模型预测得分都是0,所以$s_i=s_j=0,ρ_{ij}=1/2$,lambda(i,j)的计算公式为:
$$\begin{gather*} \lambda_{i j}=\rho_{i j} *|\operatorname{deltaNDCG}(i, j)| \end{gather*}$$上式为Ranklib中实际使用的公式,而在paper中,还需要再乘以-σ,在σ=1时,就是符号正好相反,这两种方式是等价的,符号并不影响模型训练结果(其实大可以把代码中lambda的值前面加一个负号,只是注意在每轮计算train, valid和最后计算test的ndcg的时候,模型预测的得分modelScores要按升序排列——越负的doc越好,而不是源代码中按降序。最后训练出的模型是一样的,这说明这两种方式完全对称,所以符号的问题可以省略。甚至不乘以-σ,更符合人的习惯——分数越大越好,降序排列结果:
$$\begin{gather*} \lambda_{i}=\sum_{j(l a b e l(i)>l a b e l(j))} \lambda_{i j}-\sum_{j(label(i)<label(j))} \lambda_{i j} \end{gather*}$$计算$\lambda_{1}$,由于label(1)=0,qid=1830中的其他doc的label都大于或者等于0,所以$\lambda_{1}$的计算中所有的$\lambda_{1,j}$都为负项。将之前计算的各$deltaNDCG(1,j)$代入,且初始状态下$ρ_{ij}=1/2$,所以:
$$\begin{gather*}* \begin{aligned} \lambda_{1} &=-0.5 *(\text {deltaNDCG}(1,3)+\text {deltaNDCG}(1,4)+\text {deltaNDCG}(1,6)+\text {deltaNDCG}(1,7)) \\ &=-0.5 *(0.222+0.239+0.260+0.267)=-0.495 \end{aligned} \end{gather*}$$可以计算出初始状态下qid=1830各个doc的lambda值,如下:
|
|
上表中每一列都是考虑了符号的$\lambda_{i,j}$,即如果label(i)
完成各doc的$\lambda$值计算后,Regression Tree便开始以每个doc的$\lambda$值为目标,训练模型。并在最后对叶子节点上的样本 $\lambda$均值还原成 𝛾 ,乘以learningRate加到此前的Regression Trees上,更新score,重新对query下的doc按score排序,再次计算deltaNDCG以及 λ ,如此迭代下去直至树的数目达到参数设定或者在validation集上不再持续变好(一般实践来说不在模型训练时设置validation集合,因为validation集合一般比训练集合小很多,很容易收敛,达不到效果,不如训练时一步到位,然后另起test集合做结果评估)。
Regression Tree的训练最主要的就是决定如何分裂节点。lambdaMART采用最朴素的最小二乘法,也就是最小化平方误差和来分裂节点:即对于某个选定的feature,选定一个值val,所有<=val的样本分到左子节点,>val的分到右子节点。然后分别对左右两个节点计算平方误差和,并加在一起作为这次分裂的代价。遍历所有feature以及所有可能的分裂点val(每个feature按值排序,每个不同的值都是可能的分裂点),在这些分裂中找到代价最小的。
继续上面的例子,假设样本只有上面计算出 λ 的10个:
|
|
上表中除了第一列是qid,最后一列是lambda外,其余都是feature,比如我们选择feature(1)的0.059做分裂点,则左子节点<=0.059的doc有: 1, 2, 3, 9;而>0.059的被安排到右子节点,doc有4, 5, 6, 7, 8, 10。由此左右两个子节点的lambda均值分别为:
$$\begin{gather*} \bar{\lambda}_{L}=\frac{\lambda_{1}+\lambda_{2}+\lambda_{3}+\lambda 9}{4}=\frac{-0.495-0.206-0.104-0.051}{4}=-0.214 \end{gather*}$$ $$\begin{gather*} \begin{array}{l} \lambda_{R}^{-}=\frac{\lambda_{4}+\lambda_{5}+\lambda_{6}+\lambda 7+\lambda_{8}+\lambda_{10}}{6} \\ =\frac{0.231+0.231-0.033+0.240+0.247-0.061}{6}=0.143 \end{array} \end{gather*}$$继续计算左右子节点的平方误差和:
$$\begin{gather*} \begin{aligned} &s_{L}=\sum_{i \in L}\left(\lambda_{i}-\bar{\lambda}_{L}\right)^{2}=(-0.495+0.214)^{2}\\ &+(-0.206+0.214)^{2}+(-0.104+0.214)^{2}\\ &+(-0.051+0.214)^{2}=0.118\\ &s_{R}=\sum_{i \in R}\left(\lambda_{i}-\bar{\lambda}_{R}\right)^{2}=(0.231-0.143)^{2}\\ &+(0.231-0.143)^{2}+(-0.033-0.143)^{2}\\ &+(0.240-0.143)^{2}+(0.247-0.143)^{2}\\ &+(0.016-0.143)^{2}=0.083 \end{aligned} \end{gather*}$$因此将feature(1)的0.059作为分裂点时的均方差(分裂代价)是:
$$\begin{gather*} \cos t_{0.059 @ \text { feature}(1)}=s_{L}+s_{R}=0.118+0.083=0.201 \end{gather*}$$我们可以像上面那样遍历所有feature的不同值,尝试分裂,计算Cost,最终选择所有可能分裂中最小Cost的那一个作为分裂点。然后将𝑠𝐿和𝑠𝑅 分别作为左右子节点的属性存储起来,并把分裂的样本也分别存储到左右子节点中,然后维护一个队列,始终按平方误差和s降序插入新分裂出的节点,每次从该队列头部拿出一个节点(并基于这个节点上的样本)进行分裂(即最大均方差优先分裂),直到树的分裂次数达到参数设定(训练时传入的leaf值,叶子节点的个数与分裂次数等价)。这样就完成了一棵Regression Tree的训练。
上面讲述了一棵树的标准分裂过程,此外,树的分裂还包含了其他参数设定,例如叶子节点上的最少样本数,比如我们设定为3,则在feature(1)处,0.001和0.003两个值都不能作为分裂点,因为用它们做分裂点,左子树的样本数分别是1和2,均<3。叶子节点的最少样本数越小,模型则拟合得越好,当然也容易过拟合(over-fitting);反之如果设置得越大,模型则可能欠拟合(under-fitting),实践中可以使用cross validation的办法来寻找最佳的参数设定。
【待进一步整理】