文本搜索领域常见的召回算法大致可以分为基于词汇匹配和向量召回两种,基于词汇匹配的算法以BM25为代表,通过计算query和doc词语匹配度来衡量相关性;向量化召回算法则经历了从无监督计算预训练词向量(word2vec、Glove)相似度,到有监督地计算query和doc相似度(DSSM),再到基于大规模预训练语言模型(BERT)计算相似度的迭代过程。
背景知识
基于词汇匹配-Lexical IR
代表算法为BM25,可以理解为tf-idf算法的改进,参考链接:
https://cloud.tencent.com/developer/article/1056867?from=article.detail.1331631
Lexical IR算法得益于高效的倒排索引技术,十分高效,仍是目前主要的检索方法。其主要面临以下两个问题:
- 词汇不匹配导致漏召回:例如”cat”和”kitty”都表示“猫”;
- 语义不匹配导致错召回:例如”bank of river”和”bank in finance”中的bank表示不同含义,前者是“河岸”,而后者是“银行”,当query中的bank表示银行时,可能会将包含”bank of river”的文章进行召回。
上述两个问题可以通过词形归一、N-grams匹配和查询扩展等技术进行缓解,但本质上仍然是基于词袋假设,无法从根本上解决。
向量化-Neural IR
无监督词向量
早期的无监督词向量代表模型有word2vec和Glove,计算query和doc相似度时可以有以下方法:
- 首先将query和doc各个词语映射到对应向量,然后利用max pool、avg pool等方法获得query向量和doc向量,最后利用余弦距离等计算相似度;
- 不同于方法1利用max pool、avg pool获得query向量和doc向量,方法2利用CNN/LSTM等模型进行编码,最后同样利用余弦距离等计算相似度,整体是DSSM结构;
- 无论是方法1的pool方法,还是方法2中利用模型进行编码,降维到单个向量的表示总会带来一些损失,因此方法3在token粒度增加了一些交互,代表模型为DRMM,但伴随而来的是计算复杂度的显著增大,因此一般用在后续的精排阶段,召回部分的主要目的并非是进行精准的排序,而是保证相关性较高的doc都能召回。
无监督词向量可以一定程度解决Lexical IR中的问题1,对于”cat”和”kitty”,其对应的词向量也是接近的。但对于问题2仍无法解决。
大规模预训练语言模型
BERT的出现对于Neural IR影响很大,因为向量化本质上还是解决词、句子的表示问题,通过大规模的训练预料和transformer模型,可以对词语、句子进行更好的表示。此外也可以解决Lexical IR中的问题2,因为每个词在LM中都会有其对应的表示,例如”bank of river”和”bank in finance”分别输入到transformer模型,两个”bank“的表示是不同的。而基于BERT的模型召回算法的迭代过程与上述无监督词向量部分提到的3个方法十分类似。
- 将query和doc直接拼接输入到BERT中获得对应的[CLS]表示,进行打分;除了直接拼接,还可以利用全连接交叉注意力获得词汇和语义的匹配信息,例如BERT reranker,如下图所示:

显然这里的计算量非常大,并不适用于召回阶段。 - 第二种方法是延续以DSSM为代表的dense ventor representation的思想,典型的有SententceBERT和DPR,如下图所示:
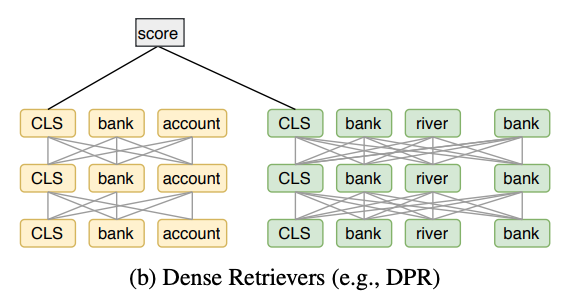
此类模型首先建立文档的向量索引,然后利用最近邻向量搜索等方法检索相关的文档。显然,这类模型缺少了query和doc的交互信息。 - DSSM模型的一个问题是将query和doc表示为一个dense ventor时不可避免的会丢失一些信息,一些模型在这方面做了改进,例如Poly-encoder将query编码为一组向量,将document编码为单个向量。Me-BERT将query编码为单个向量,将document编码为一组向量。ColBERT将query和document均编码为一组向量,然后在token级别进行all-to-all的匹配,模型结构如下图所示:
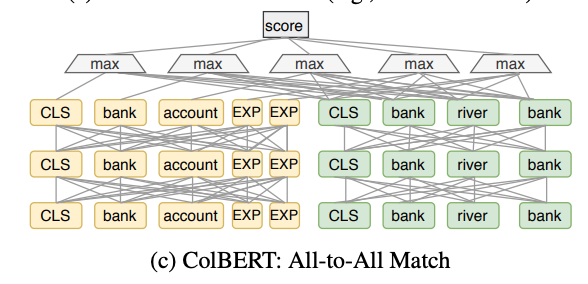
由于ColBERT对doc中的token都进行了编码,因此建立索引时需要考虑文档中所有token向量,相比于DPR,索引的复杂度大大增加,并且在查询过程中需要遍历所有索引,因此ColBERT在召回阶段有学术参考价值,工业上难以使用,对硬件资源要求太高。参考DPR和ColBERT,作者提出了COIL模型,其复杂度和检索速度接近DPR,同时检索准确率接近ColBERT。
模型实现
Lexical IR实现
COIL参考了Lexical IR的倒排索引思想,这里简单介绍一下经典的Lexical IR系统。以BM25算法为例,利用词语匹配分数来衡量query和doc的相关性,具体的函数可以基于词频(TF)和逆文档频率(IDF)来设计,下面是一种通用的数学定义方式:
$\begin{gather*}s=\sum_{t \in q \cap d} \sigma_{t}\left(h_{q}(q, t), h_{d}(d, t)\right) \end{gather*}$
其中$t$表示query和doc匹配的词语,$h_q$和$h_d$用于输出该词语相关信息,$\sigma_t$表示打分函数,根据该定义,BM25算法可以表示为:
$$\begin{gather*}
\begin{array}{c}
s_{\mathrm{BM} 25}=\sum_{t \in q \cap d} i d f(t) h_{q}^{\mathrm{BM} 25}(q, t) h_{d}^{\mathrm{BM} 25}(d, t) \\
h_{q}^{\mathrm{BM} 25}(q, t)=\frac{t f_{t, q}\left(1+k_{2}\right)}{t f_{t, q}+k_{2}} \\
h_{d}^{\mathrm{BM} 25}(d, t)=\frac{t f_{t, d}\left(1+k_{1}\right)}{t f_{t, d}+k_{1}\left(1-b+b \frac{|d|}{\mathrm{avgdl}}\right)}
\end{array}
\end{gather*}$$
其中$tf_{t,q}$和$tf_{t,d}$分别表示词语$t$在query和doc中的词频,$idf(t)$表示$t$的逆文档频率,$b, k_1, k_2$均为超参数。
Lexical IR的高效在于倒排索引,在实际检索时,不需要访问语料库中所有doc,而只需要访问词语对应的倒排索引的子集,如下图所示:
COIL模型设计和训练
Lexical IR模型中计算query和doc的相关性依赖于词语的精确匹配和TF-IDF的打分规则,那么是否可以利用上下文语义打分模型进行替换呢?COIL模型以此为出发点进行了改进,首先将query和doc的token编码为上下文向量:
$$\begin{gather*}\begin{aligned}
\boldsymbol{v}_{i}^{q} &=\boldsymbol{W}_{t o k} \operatorname{LM}(q, i)+\boldsymbol{b}_{t o k} \\
\boldsymbol{v}_{j}^{d} &=\boldsymbol{W}_{t o k} \operatorname{LM}(d, j)+\boldsymbol{b}_{t o k}
\end{aligned}\end{gather*}$$
其中$\boldsymbol{W}_{\text {tok }}^{n_{t} \times n_{l m}}$用于将$n_lm$维向量映射到更低维的$n_t$维向量,后续实验也证明了低维向量就可以很好地编码token级别的信息。
根据上文提到的Lexical IR的数学定义,基于上下文词向量的词语匹配打分函数可以定义为:
$\begin{gather*}s_{\mathrm{tok}}(q, d)=\sum_{q_{i} \in q \cap d} \max _{d_{j}=q_{i}}\left(\boldsymbol{v}_{i}^{q \top} \boldsymbol{v}_{j}^{d}\right)\end{gather*}$
其中$q_{i} \in q \cap d$表示query和doc中精确匹配的词语,具体的计算过程是:对于query中的每个词$q_i$,在doc中匹配到相同的词$d_j=q_i$,然后计算$d_j$和$q_i$的点积相似度,并取出所有$d_j$中的最高相似度,这里的$max$可以捕获query和doc最重要的语义匹配信号。
由于采用Lexical IR中的精确匹配,仍然可能会遇到背景知识Lexical IR中提到的问题1,可以引入句子级的表示[CLS]:
$$\begin{gather*}\begin{array}{l}
\boldsymbol{v}_{c l s}^{q}=\boldsymbol{W}_{c l s} \mathrm{LM}(q, \mathrm{CLS})+\boldsymbol{b}_{c l s} \\
\boldsymbol{v}_{c l s}^{d}=\boldsymbol{W}_{c l s} \mathrm{LM}(d, \mathrm{CLS})+\boldsymbol{b}_{c l s}
\end{array}\end{gather*}$$
其中$\boldsymbol{v}_{c l s}^{q}$和$\boldsymbol{v}_{c l s}^{d}$之间的相似度可以从语义级别进行匹配,缓解精确匹配导致的漏召回问题,COIL模型最终的打分函数为:
$\begin{gather*}s_{\text {full }}(q, d)=s_{\text {tok }}(q, d)+\boldsymbol{v}_{c l s}^{q}{ }^{\top} \boldsymbol{v}_{c l s}^{d}\end{gather*}$
论文中将包含[CLS]匹配的模型成为COIL-full,只包含词语匹配的称为COIL-tok,COIL-full模型如下图所示: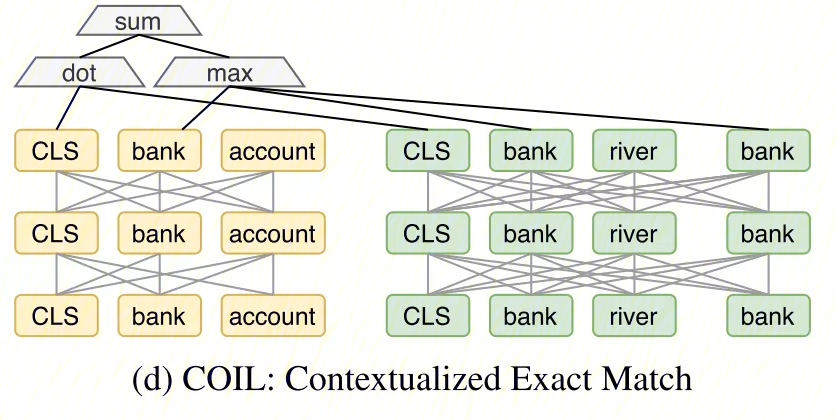
通过优化负对数似然函数来训练模型:
$\begin{gather*}\mathcal{L}=-\log \frac{\exp \left(s\left(q, d^{+}\right)\right)}{\exp \left(s\left(q, d^{+}\right)\right)+\sum_{l} \exp \left(s\left(q, d_{l}^{-}\right)\right)}\end{gather*}$
其中$d^+$表示正样本,$d^-$表示负样本。
检索过程
索引方式与Lexical IR类似,如下图所示: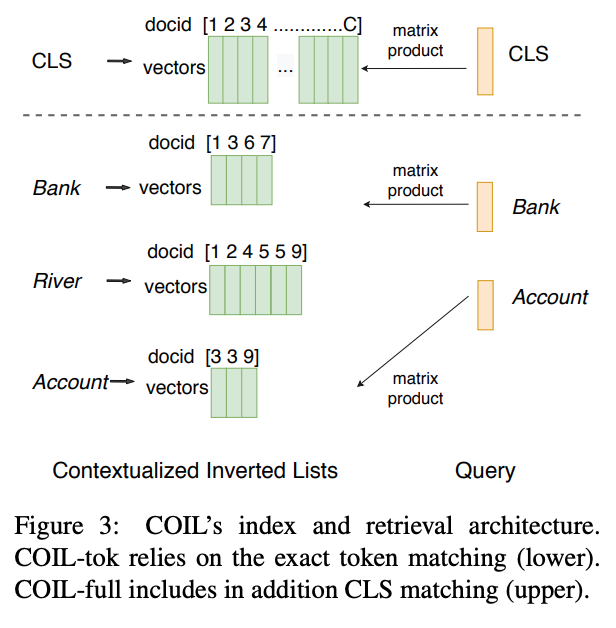
具体地,预先计算doc的所有向量,$\begin{gather*}I^{t}=\left\{\boldsymbol{v}_{j}^{d} \mid d_{j}=t, d \in C\right\}\end{gather*}$
其中C表示所有文档,$\boldsymbol{v}_{j}^{d}$表示token编码,最终得到所有$t$的倒排索引$\mathbb{I}=\left\{I^{t} \mid t \in V\right\}$,对于COIL-full,还需要加入$I^{c l s}=\left\{\boldsymbol{v}_{c l s}^{d} \mid d \in C\right\}$。
为了加速,在检索时,可以将对应的多个token向量$I^{t}$转化为一个矩阵$M^{n_{t} \times\left|I^{k}\right|}$,同样可以将对应的多个[CLS]向量$\boldsymbol{v}_{c l s}^{d}$整合为一个矩阵$M_{c l s}$,将相似度计算转化为高效的矩阵向量积。
单个doc建立索引的过程如下图所示: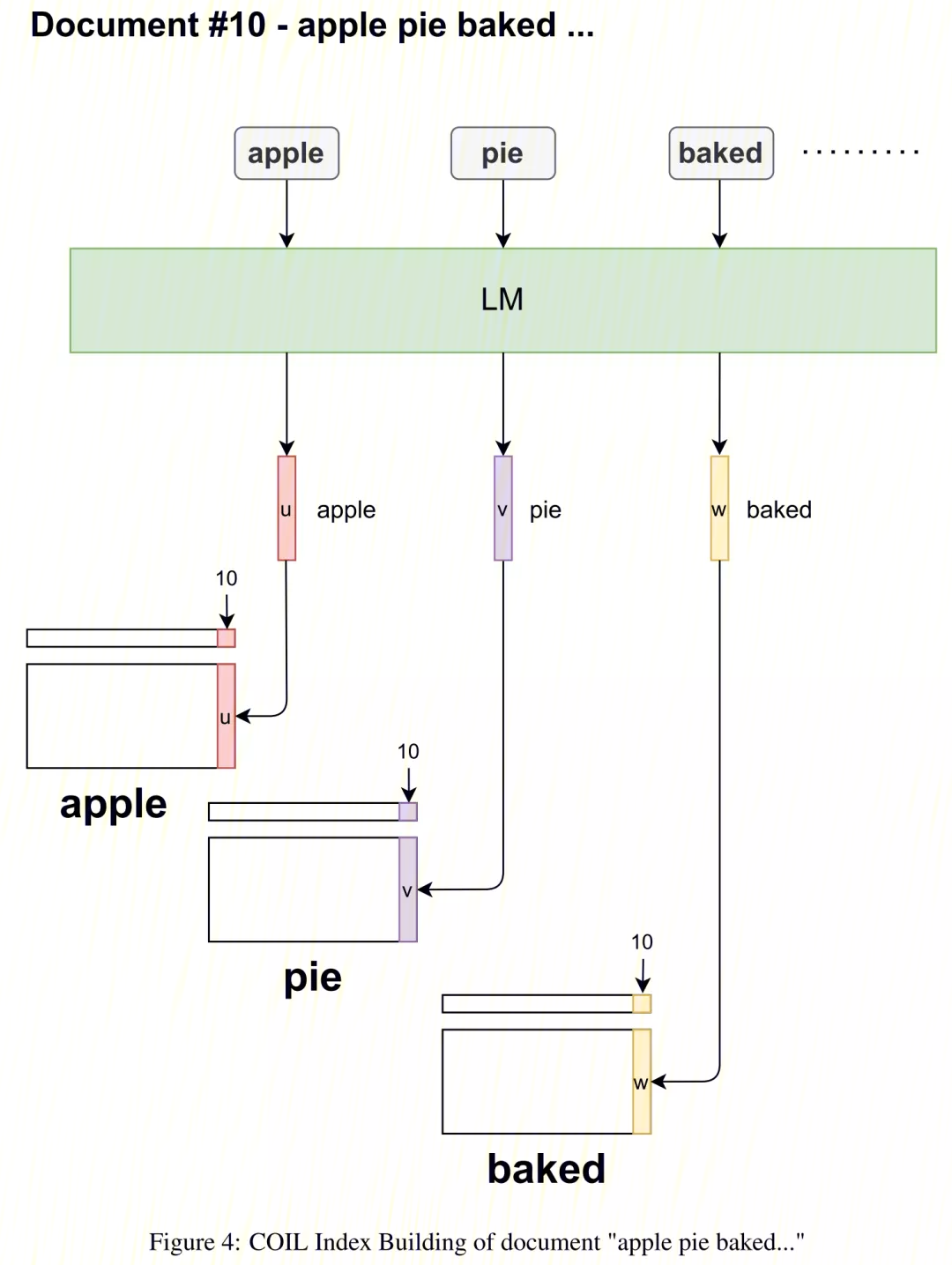
检索时,给定一个query,模型首先将query中所有token编码为向量$\boldsymbol{v}_{i}^{q}$,然后通过预先建立的倒排索引获取候选子集$\mathbb{J}=\left\{I^{t} \mid t \in q\right\}$,其中$|\mathbb{J}|<<|\mathbb{I}|$,最后通过矩阵向量乘法计算query和doc的匹配分数,如下图所示: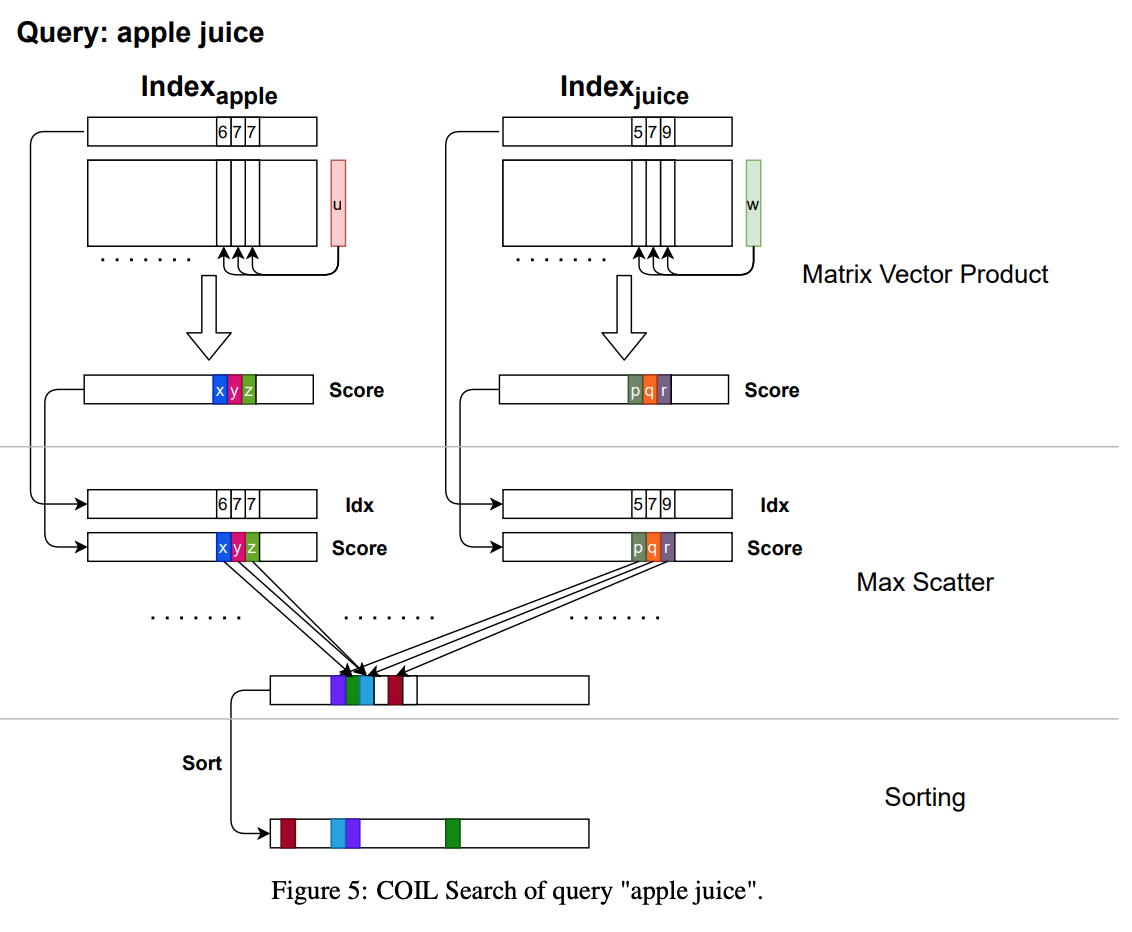
实验结果
作者在MSMARCO passage(8M英文文章,平均长度60)和MSMARCO document(3M英文文档,平均长度900)数据集上测试了不同模型,结果如下图所示: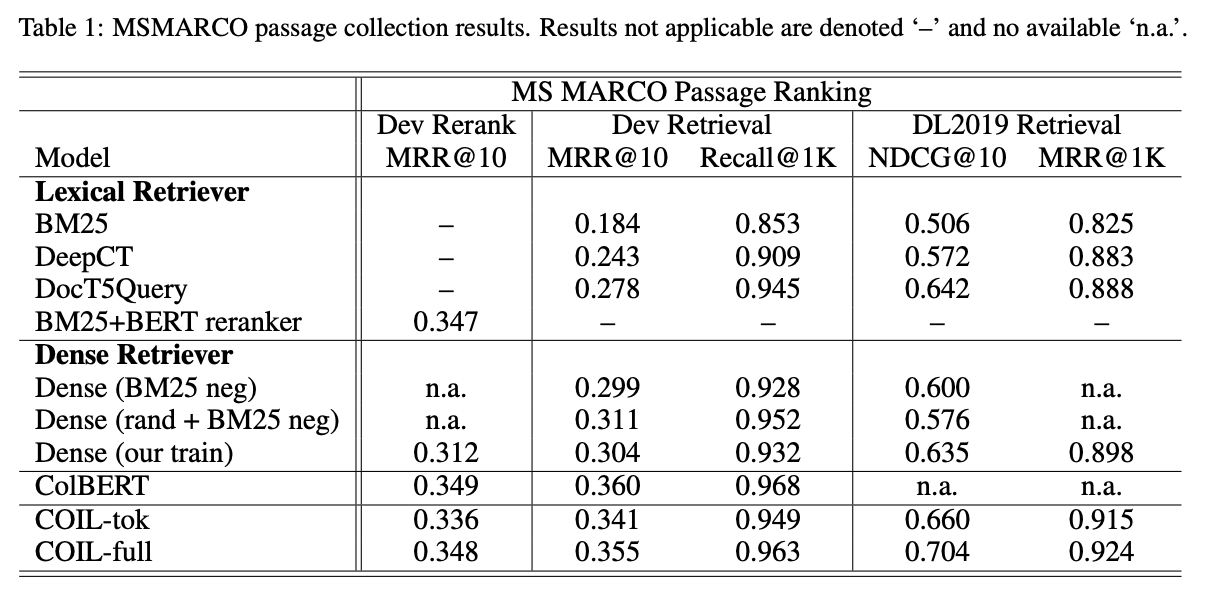

实验结果表明COIL-tok优于所有基于词语匹配的检索方法,也优于所有基于Dense vector的检索方法,COIL-tok模型在提升precision的同时可以保证recall无明显下降,加上[CLS]匹配后的COIL-full模型取得了进一步提升。COIL-full通过精确匹配query和doc的词语,有效的捕获了重要的匹配信息,通过忽略相关性较低的词语之间的匹配计算,可以显著地减少计算量,同时获得与ColBERT接近的表现。
向量维度分析
文中实验表明,将[CLS]从768维降到128维会导致效果轻微的下降,而将$n_t$从32降到8所带来的影响很小,这也符合直观理解。句子、文章显然需要更高的维度进行编码,而词语需要的维度较少,降维可以提高模型推理速度,使得COIL模型比DPR更快,甚至接近传统的BM25模型。为了进一步提升速度,还可以考虑采用近似搜索、量化压缩等方法。此外,为防止单个token对应的倒排链过长,我们可以只对doc中重要词建立索引,并在建立索引时预先进行排序。实验结果如下图所示:
CASE分析
对比DPR这种基于Dense vector的检索模型,COIL针对token学习一个词语级别的向量,可有效区分同一个token在不同上下文中的语义差异。如下图所示:
第一个query中的词“cabinet”在第一个文档中是“内阁”的意思,而在第二个文档中是“橱柜”的意思,而query中的cabinet是第一种含义,因此COIL赋予了第一个文档中的cabinet更高的匹配分数。
第二个query中,pass在这两个文档中都是“许可”的意思,但经过上下文化之后,COIL能够捕捉到priority pass这个整体概念,因此赋予了第一个文档更高的匹配分数。
第三个query中,is是一个停用词(stopwords),在Lexical IR中,一般会丢弃停用词,然而在这个例子中可以观察到COIL能够区分解释句中的is和被动语态中的is的区别,因为第一个文档中的is是解释定义,查询句中的is也是寻求解释,因此COIL赋予了第一个文档更高的匹配分数,同时由于is过于常见,COIL也并没有像前面两个例子那样为is赋予过高的权重。不过在工业界实际实现时,考虑到速度和资源限制,这些停用词大概率还是会去掉的。
上述例子说明COIL通过引入语义信息,可以有效地解决词汇不匹配和语义不匹配的问题,优于单纯的字面匹配检索系统。
结论
Lexical IR和Neural IR结合效果好,COIL是一个很好的尝试,在precision和recall上均取得了不错的结果,并且推理过程十分高效,具有应用价值。