NLP领域最基础但也最重要的问题是如何表示词语、句子和篇章,word2vec的出现是一个很大的进步,可以将词语编码为包含语义信息的向量,通过向量之间的距离可以在一定程度上衡量词语的相似度。得益于深度学习技术的发展,在获得词语向量表示后,可以利用CNN、LSTM和Transformer等模型对句子和篇章进行表示。但是深度学习模型需要大量数据来学习文本的表示,训练数据的质量和数量常常制约了模型的效果,以BERT为开端,大规模预训练语言模型开始得到广泛应用。
BERT论文地址:https://arxiv.org/pdf/1810.04805.pdf
BERT-base、GPT和ELMo模型如下图所示:

BERT中使用了Transformer对文本序列进行处理。
Transformer论文地址:https://arxiv.org/pdf/1706.03762.pdf
Transformer中的self-attention机制相比LSTM能捕获更长距离的文本信息,而且可以并行计算。但是当文本序列过长时,self-attention的计算复杂度会相当大,假设文本长度为n,self-attention的计算复杂度是$o(n^2)$。此外,Transformer对文本序列中位置信息的感知依赖position encoding方法,base版本中的编码方式效果一般。
传统的RNN模型由于反向传播算法带来的梯度衰减和梯度爆炸问题,只能处理较短的文本。LSTM、GRU模型利用门机制进行改进,将梯度计算中的连乘改为连加,一定程度上提升了模型长距离获取信息的能力,但梯度衰减的问题并没有根本解决,其能处理的文本最大长度一般是400。如果没有内存和算力的限制,理论上Transformer可以处理任意长度的文本,实际应用时一般将长度设置为512。那么对于长度超过512的文本,改如何处理呢?
一个很自然的想法是将文章切分为多个长度为512的片段,分别利用BERT处理,最后合并为整体的编码,当然各个BERT的输出结果也可以利用CNN和LSTM进一步处理,如下图所示:

上文中已经提到BERT-base版本使用的Transformer计算复杂度较高,且固定长度的分片方式也会割裂片段之间的上下文联系,学术界基于Transformer做了很多改进,优化方法主要有降低序列长度、减少attention复杂度和缩小矩阵维度等,大致可以分为以下几类:
- 固定模式(Fixed Patterns)。设置固定大小的窗口、步幅等,进一步分为:
- 分块模式。将长度为N的序列切分为若干个长度为B的块,复杂度可以从N*N降至B*B;
- 步长模式。例如只在固定间隔进行attention操作,例如Longformer中使用的空洞窗口,这一部分会在后面Longformer模型部分进行介绍;
- 压缩模式。例如通过卷积、池化将原始序列降维到一个固定长度。
- 组合模式(Combination of Patterns)。在降低内存复杂度方法上与Fixed Patterns类似,不同的是通过组合多种访问模式可以提高self-attention机制的覆盖范围。
- 可学习模式(Learnable Patterns)。与固定模式不同,该模式通过数据驱动来学习访问模式,关键思想是基于token的相关性进行聚类或者分桶,而相关性函数也是在端到端的训练中学习的。可学习模式仍是基于Fixed Patterns来优化,通过对输入的token进行排序和聚类,可以更好的获取序列的全局信息。
- 存储(Memory)。使用额外的存储模块来同时访问多个token。一种常见的形式是global memory,可以访问整个序列。例如Longformer模型中,对于一些关键token,允许其在整个序列上进行attention计算。
- 矩阵降秩(Low-Rank Methods)。利用self-attention矩阵的低秩近似来提升效率。
- 内核(Kernels)。通过内核化方式提升计算效率,其中核是self-attention矩阵的近似,因此可以看做降秩方法的一种。
- 递归(Recurrence)。对分块方法很自然的改进是利用递归将各个块进行连接,典型的模型是Transformer-XL。
根据上述标准可以对主流的模型进行分类:
![]()
各模型对应的复杂度如下表所示:
![]()
当然分类的标准并不唯一,这里是参考Efficient Transformers: A Survey一文。
下面对Transformer-XL和Longformer模型进行介绍,其他模型等待后续更新。
Transformer-XL
BERT-base版本默认处理的最大文本长度是512,通过将长文本切分为多个固定长度的段落,可以扩展可处理的文本长度,但仍然存在以下问题:
- 训练时多个segment之间相互独立,无法有效的获得上下文信息,导致文本编码碎片化,影响最终性能;
- 预测时,decoder生成每一个字时都伴随着一次移动,没有重复利用之前的信息,计算复杂度高,效率低下:
train过程:
![]()
evaluate过程:
![]()
针对以上问题,Transformer-XL进行了改进,在编码第i+1个segment时,对第i个segment的信息进行缓存。第i+1个segment进行attention计算时,会融合前一个segment的信息,实现片段级别的递归。预测时同样会缓存segment的隐层信息,可以极大的提升预测速度,文中实现表明相对原始的Transformer可以提升1800倍,这里也体现出原始的Transformer实在是太慢了。
Transformer-XL的train过程:
![]()
Transformer-XL的evaluation过程:
![]()
采用segment递归可以有效捕获分片之间的联系,但随之产生的一个问题是原始的位置编码方式不再可用,因为无法区分不同分片中的相同位置,如下边公式所示:
$$\begin{gather*} \begin{aligned} \mathbf{h}_{\tau+1} &=f\left(\mathbf{h}_{\tau}, \mathbf{E}_{\mathbf{s}_{\tau+1}}+\mathbf{U}_{1: L}\right) \\ \mathbf{h}_{\tau} &=f\left(\mathbf{h}_{\tau-1}, \mathbf{E}_{\mathbf{s}_{\tau}}+\mathbf{U}_{1: L}\right) \end{aligned} \end{gather*}$$其中$\mathbf{E}_{\mathbf{s}_{\tau}} \in \mathbb{R}^{L \times d}$表示$\mathbf{S}_{\tau}$序列的向量,$\mathbf{h}_{\tau}$表示第$\tau$个segment的隐层状态,$\mathbf{U}_{1: L}$表示$\mathbf{E}_{\mathbf{s}_{\tau}}$对应的位置编码,L表示序列长度。可以看到对于序列$\mathbf{S}_{\tau}$和$\mathbf{S}_{\tau+1}$都使用了相同的位置编码$\mathbf{U}_{1: L}$,对于$j=1,..,L$,模型无法区分词语$x_{\tau, j}$和$x_{\tau+1, j}$的位置差异。
值得注意的是,原始Transformer中使用的绝对位置编码,在进行点积操作时能反应两个token的相对距离,但是不具有方向性,且相对距离的信息也会被注意力计算破坏。
参考TENER一文中的实验结果:

图中d表示向量维度,横轴k表示两个词的距离,纵轴表示点乘结果。
对于向量$P E_{\text {pos }}$和$P E_{\text {pos +k}}$而言,两者的点乘结果只取决于偏移量k,从上图看出点乘的结果是对称的,因此有$P E_{\text {pos }}^{\top} P E_{\text {pos-k }}=P E_{\text {pos }}^{\top} P E_{\text {post } k}$,显然这种编码方式是无法反映方向的。
此外,在Transformer中,原始的向量x会经过对应的矩阵映射到q,k和v向量,TENER中通过随机矩阵进行模拟,如下图所示:
![]()
可以看到,经过矩阵变换后,点积的结果并不能有效的反映向量之间的距离。
回到Transformer-XL,模型中使用了相对位置编码替代了绝对位置编码。位置编码的作用是什么,是否一定要在初始输入的向量表示中引入呢?位置信息的作用是影响attention score,直观的说在我们平时阅读文本的时候,也会根据词语之间的距离、顺序来判断相关性,因此可以在attention计算时引入位置信息,而不是在初始输入,同时可以避免矩阵变换的影响。对于同一片段内的$q_i$和$k_j$,其注意力得分计算公式为:
$$\begin{gather*} \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{abs}} &=\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}}_{(a)}+\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j}}_{(b)} \\ &+\underbrace{\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}}_{(c)}+\underbrace{\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j}}_{(d)} \end{aligned} \end{gather*}$$其中$\mathbf{A}_{i, j}^{\mathrm{abs}}$表示绝对编码方式对应的attention score,$\mathbf{E}_{x_{i}}$表示词语$x_i$对应的向量,$U_i$表示$x_i$对应的位置编码,$W_k, W_q$表示参数矩阵。由于使用了相对位置编码($U_i$这种仅对应一个位置的编码失去意义),上述公式需要进行改变,如下所示:
$$\begin{gather*} \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{rel}} &=\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k, E} \mathbf{E}_{x_{j}}}_{(a)}+\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k, R} \mathbf{R}_{i-j}}_{(b)} \\ &+\underbrace{u^{\top} \mathbf{W}_{k, E} \mathbf{E}_{x_{j}}}_{(c)}+\underbrace{v^{\top} \mathbf{W}_{k, R} \mathbf{R}_{i-j}}_{(d)} \end{aligned} \end{gather*}$$具体的改动有:
- 将(b)和(d)中的绝对位置编码$U_j$替换为相对位置编码$R_{i-j}$,注意这里的$R$并不是可学习的,而是采用了类似原始Transformer中的三角函数编码矩阵,只需要把公式中的pos替换为$i-j$即可。
- 使用可训练参数$u \in \mathbb{R}^{d}$替代原来(c)中的$\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top}$。对于query中的词语,其对应的位置向量是相同的,因此在计算attention score时受到的关注也是相同的。类似地,使用$v \in \mathbb{R}^{d}$代替(d)中的\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top}。
- 将原来的$W_k$矩阵分为两个权重矩阵$\mathbf{W}_{k, E}, \mathbf{W}_{k, R}$,分别用来生成基于内容和基于位置的健值向量。
公式中的四个部分:
- (a)表示query token encoding和key token encoding之间的关联信息;
- (b)表示query token encoding和query-key relative position encoding之间的关联信息;
- (c)表示query整体的position encoding与ker token encoding之间的关联信息;
- (d)表示query整体的position encoding和query-key relative position encoding之间的关联信息。
上文中也提到,Transformer-XL中的相对位置编码$R$采用了类似原始Transformer中的三角函数编码方式,因此也无法体现方向性,可以参考Self-Attention with Relative Position Representations进行改进。当然位置编码方式还有很多种,这里不再展开。
文中在WikiText-103 、enwik8 和text8 等数据集上进行了实验,Transformer-XL模型在PPL指标上取得了较好的效果,与原始的Transformer相比,预测速度大大提升,具体内容参考原论文内容。
Longformer
论文主要改进点为减少attention计算量,提出了三种稀疏attention计算方式,如下图所示:
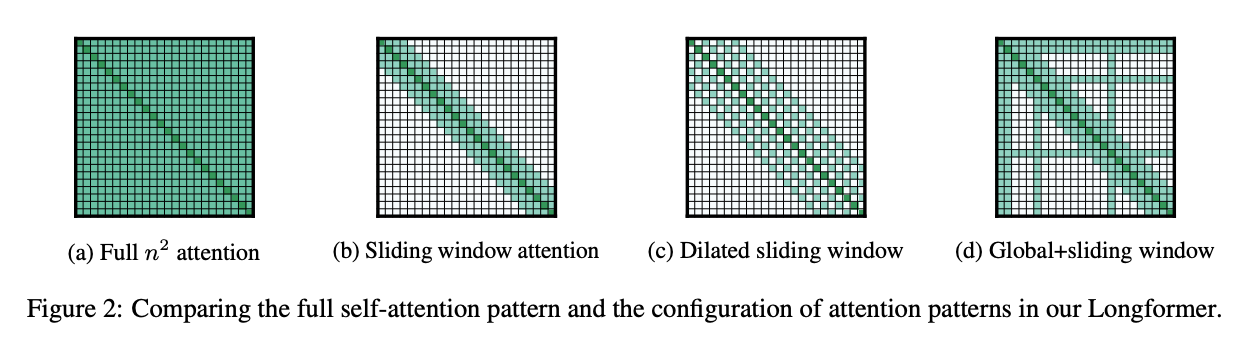
其中(a)表示原始Transformer中的attention方式,文中新提出的三种方式:
滑动窗口(Sliding Window)。对于每个token,只计算其与附近w个token的attention分数,复杂度由$o(n * n)$变为$o(w * n)$。作者认为对于不同的任务,可以在Transformer的每一层设置不同大小的窗口,以此提升模型性能。对于窗口大小,作者在具体实现时仍然采用了512,与BERT一致;
膨胀滑动窗口(Dilated Sliding Window)。当窗口大小为w时,普通的滑动窗口只能捕获长度为w的上下文,而膨胀滑动窗口可以捕获更长的上下文信息。其思想参考了空洞卷积(dilated convolution)。
空洞卷积产生于图像分割领域,传统的做法是先使用CNN卷积后接pooling操作,通过降低图像尺寸来增大感受野。但是图像分割的预测是pixel-wise的输出,所以一般通过反卷积进行upsampling来较小的图像尺寸恢复到原始尺寸。显然,尺寸先压缩再恢复的过程必然带来信息损失,那么有没有一种方式既能增大感受野,又不用pooling进行压缩呢,答案便是空洞卷积。原始的卷积方式:

空洞卷积方式:

参考空洞卷积,在滑动窗口中设置大小为d的膨胀系数,可以扩大attention计算的上下文范围;
融合全局信息的滑动窗口(Global Attention)。在某些关键token上进行全局attention计算,其他位置采用滑动窗口方式,那么什么是关键token呢?例如文本分类问题中的[CLS],QA中question的token。所谓的全局attention就是该token与所有token进行attention计算,在计算非关键token时,注意也要计算其与关键token的attention分数。
由于目前的深度学习库中没有直接实现膨胀滑动窗口的接口,作者自定义了CUDA内核操作,加快了运行速度。
作者在text8和enwik8两个字符级任务上进行了实验,底层使用较小的滑动窗口,用于捕获局部信息,高层使用较大的滑动窗口,用于捕获全局信息,在BPC(bits-per-character)指标上取得了SOTA效果。具体内容参考原论文。
实践效果
在多个收集到的中文数据集上测试,BERT-CNN、Transformer-XL和Longformer模型相比于原始的BERT模型提升并不明显,大约1%左右,而且文本起始的内容对最终结果影响最为显著。当然这个结果与具体数据集有关,仅作为参考。
[更多模型,未完待续…]
参考资料
Efficient Transformers: A Survey
Longformer:超越RoBERTa,为长文档而生的预训练模型
Convolutional Neural Networks for Sentence Classification
TENER: Adapting Transformer Encoder for Named Entity Recognition