论文发表于2017.7.14,作者为Zhiguo Wang等人,属于IBM Watson实验中心,截止2017.8.6,在TREC QA数据集上测试准确率排名第一。论文的主要目标是解决自然语言句子匹配的问题,在释义识别、自然语言推断和答案选择三个方面均取得了state-of-the-art水平。
模型结构
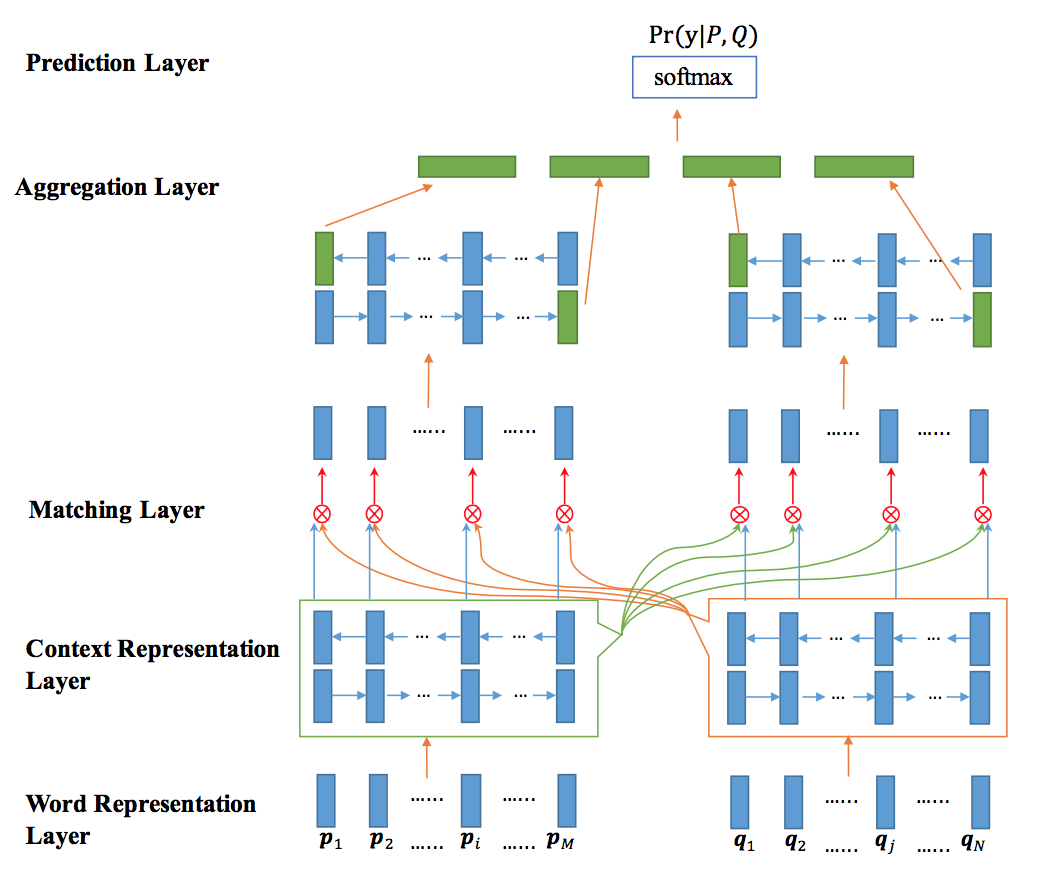
模型自下而上分为五层,分别为单词表示层、文法表示层、匹配层、聚合层和预测层,其中匹配层为模型的核心,文中共提出了四种匹配策略,这里的匹配也就是Attention机制。
假设要匹配的句子分别为P和Q。下面以P->Q方向为例进行说明,Q->P方向同理。
单词表示层
单词级别使用了GloVe模型,字符级别对字符embedding进行随机初始化,逐个输入LSTM,在训练中进行学习,由单词中的字符组成单词的向量表示。
文法表示层
使用双向LSTM对P和Q进行编码。
匹配层
本层是模型的核心层,包含四种匹配策略,分别为:Full-Matching、Maxpooling-Matching、Attentive-Matching和 Max-Attentive-Matching。在介绍四种匹配策略之前,先对论文的关键点Multi-Perspective进行说明。
Multi-Perspective
l表示perspectives数,W是一个可训练的参数矩阵,维度为l * d。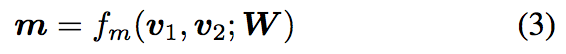
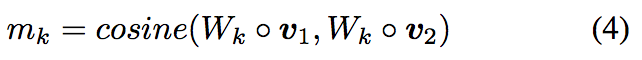
根据上面的公式,每两个向量的匹配结果为一个l维的向量m,m = [m1,…,mk,…,ml]。
four matching strategies
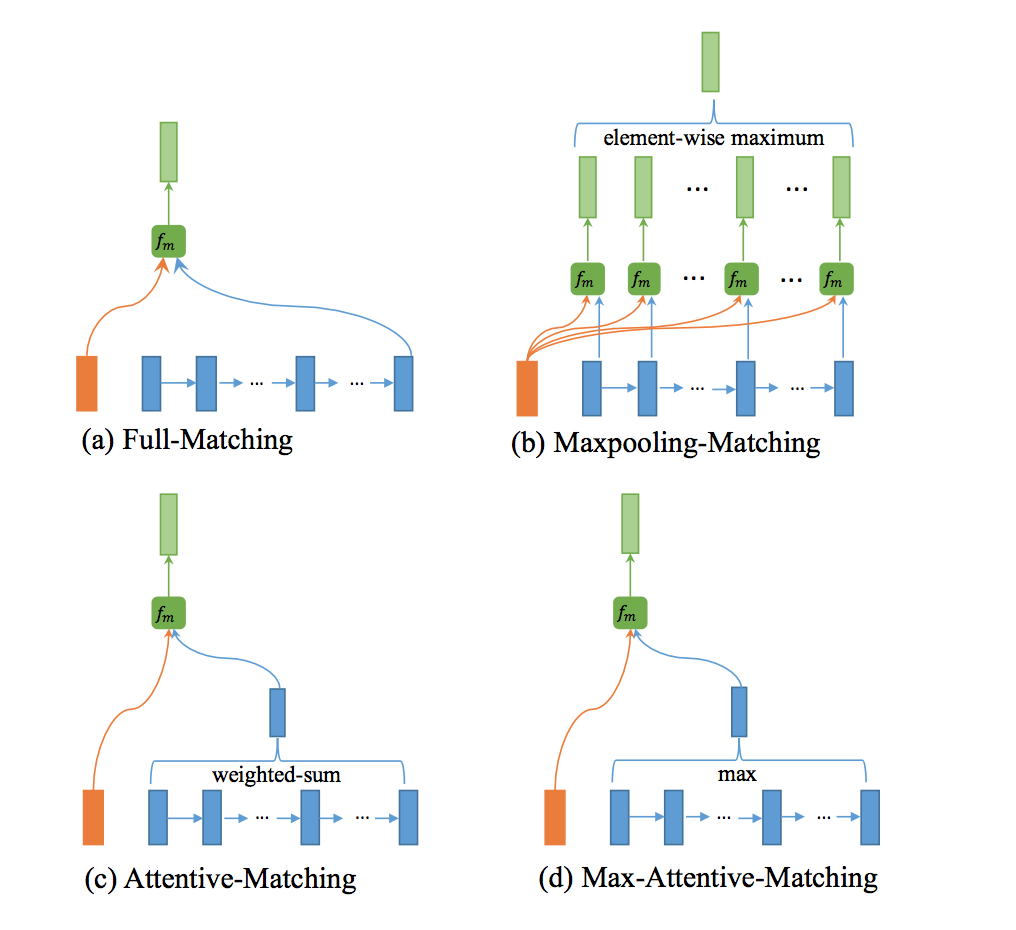
Full-Matching
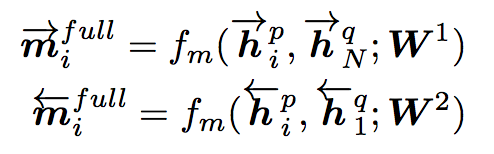
P中每一个前向(反向)文法向量与Q前向(反向)的最后一个时间步的输出进行匹配。
Maxpooling-Matching
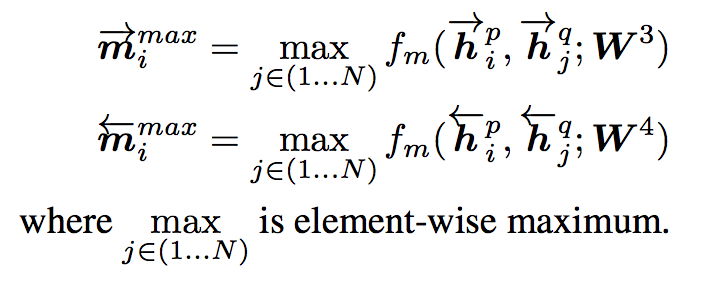
P中每一个前向(反向)文法向量与Q前向(反向)每一个时间步的输出进行匹配,最后仅保留匹配最大的结果向量。
Attentive-Matching
先计算P中每一个前向(反向)文法向量与Q中每一个前向(反向)文法向量的余弦相似度,然后利用余弦相似度作为权重对Q各个文法向量进行加权求平均作为Q的整体表示,最后P中每一个前向(后向)文法向量与Q对应的整体表示进行匹配。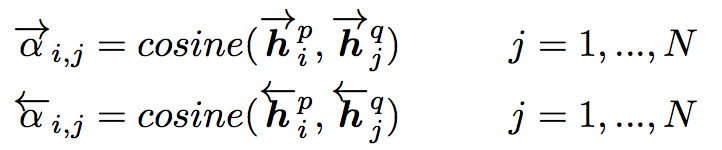
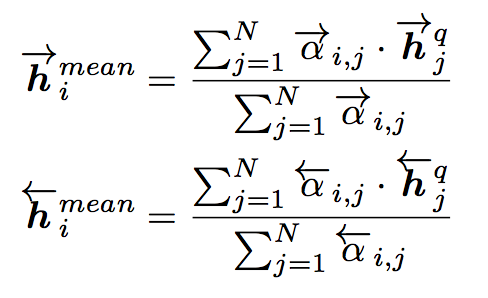
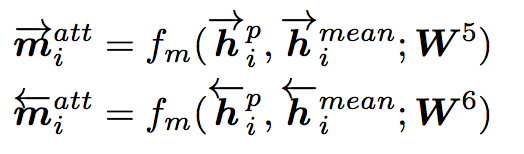
Max-Attentive-Matching
与Attentive-Matching类似,不同的是不进行加权求和,而是直接取Q中余弦相似度最高的单词文法向量作为Q整体向量表示,与P中每一个前向(反向)文法向量进行匹配。
聚合层
利用双向LSTM对匹配层输出的匹配向量进行处理,取得P、Q前向和后向最后一个时间步的输出向量,连接后输入预测层。
预测层
利用一个两层的前向神经网络处理固定长度的匹配向量,在输出层应用softmax函数获得Pr(y|P,Q)。
Experiments
the influence of multi-perspective cosine matching function
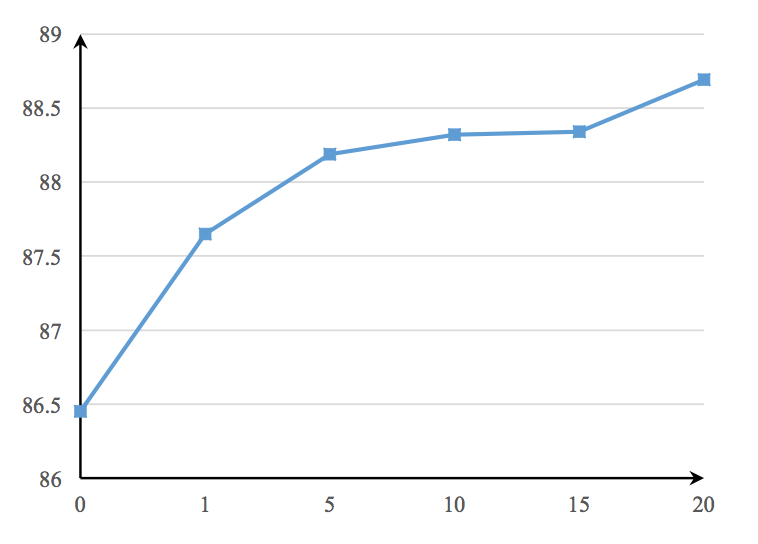
l=0时相当于直接计算余弦相似度。
Experiments on Answer Sentence Selection
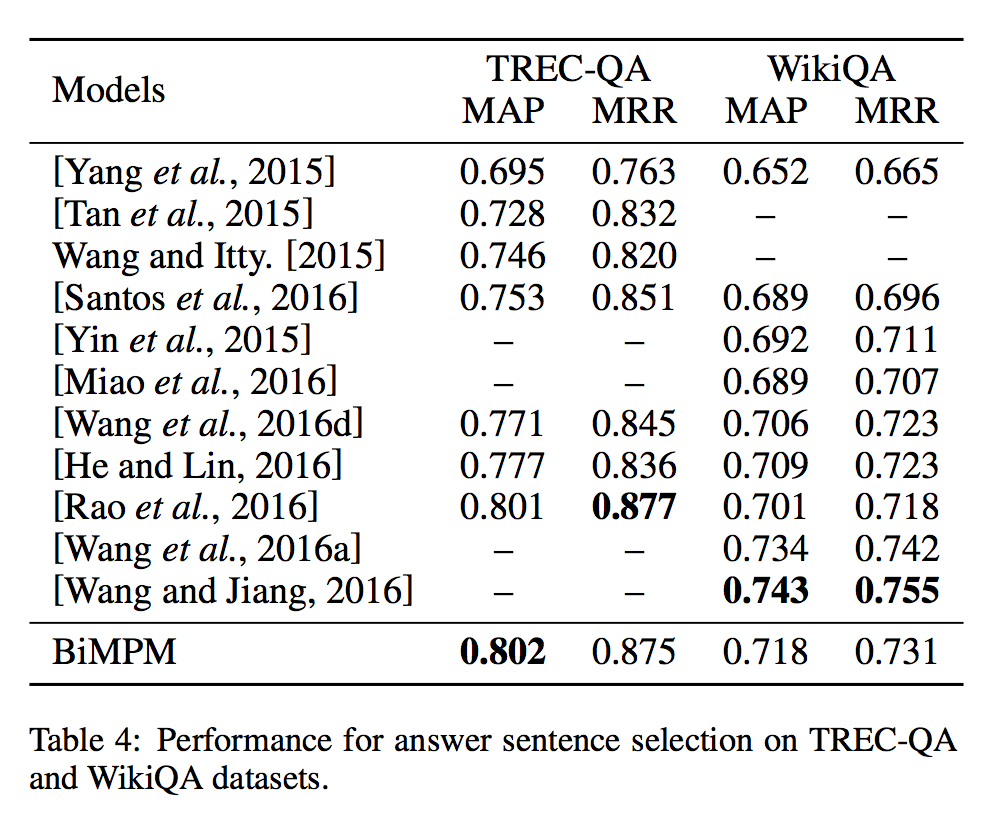
截止2017.8.7,在TREC-QA数据集上的表现算是并列第一吧。