简介
机器问答是自然语言处理领域的核心任务,一个典型的开放式问答系统分为三个部分:(1) 问题分析和候选篇章检索;(2) 候选篇章排序;(3)答案选择。本文主要关注答案选择部分,传统的模型大多基于特征工程实现,使用词法、句法和语法等特征,需要额外的资源,一旦外部工具出错,模型性能会受到影响,并且外部资源的获得也需要付出一些成本。深度学习模型可以自动学习这些特征,通过将句子映射到一个向量空间,然后在隐藏空间对问题和候选答案匹配完成答案选择,在众多数据集的测试结果均优于传统模型。本文从基本模型Siamese Network开始、逐个介绍了模型的改进版本Attention Network和Compare-Aggregate Network,随后对匹配函数选择和如何利用句子不相似部分两个点进行了说明。此外为方便对各模型进行比较,文章最后收集了各模型在WikiQA数据集上的实验结果并进行了展示。
注:本文所使用的图片均来自对应论文。
基本模型Siamese Network
Siamese网络[1]的特点是包含两路结构非常相似的网络,网络之间的参数共享,在最后进行连接,适用于计算两路输入信息的相似性。
Attentive pooling networks
dos Santos在根据Query选择Candidate answer一文[2]中使用了Siamese网络作为Baseline。模型如下图所示: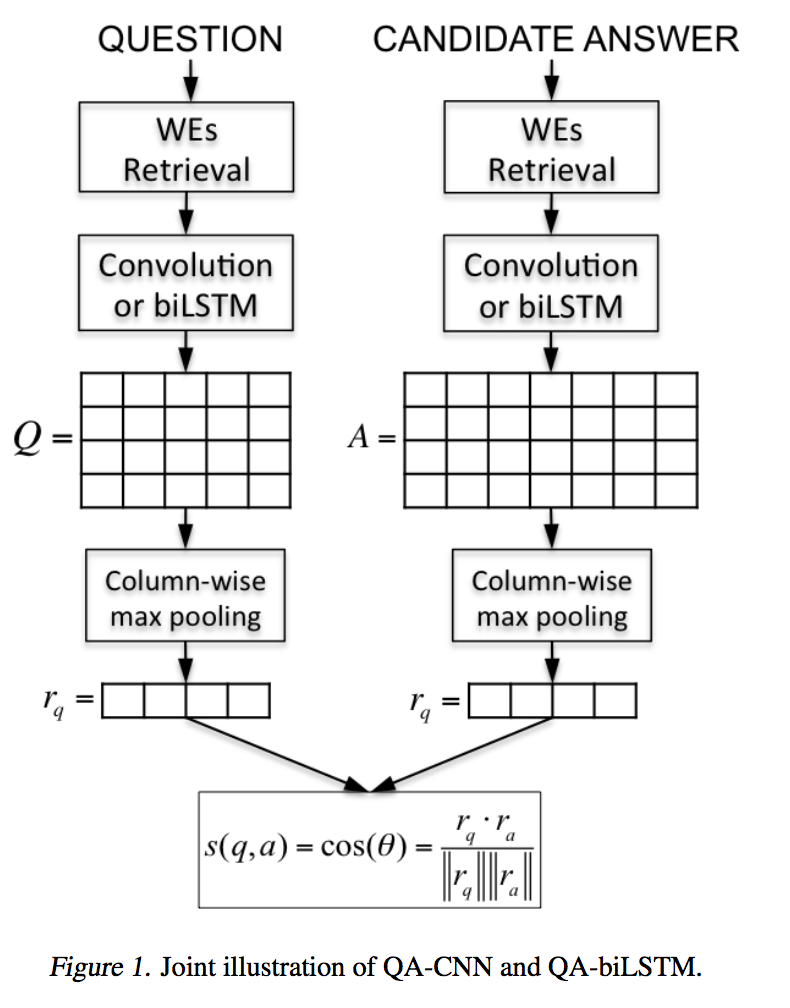
Question和Candidate answer中的每个单词首先经过word embedding处理后获得Question和Candidate answer对应的表示矩阵,然后分别利用CNN或者BiLSTM处理后获得对应的特征矩阵,在特征矩阵上应用Column-wise max pooling后获得Question和Candidate answer对应的向量$r_q$和$r_a$,最后计算两个向量之间的余弦相似度。模型的损失函数采用Hinge loss函数,即:$L=max\{0,m-s_\theta(q,a^+)+s_\theta(q,a^-)\}$
Multi-Perspective Sentence Similarity Modeling with Convolutional Neural Networks
Hua He[3]于2015年提出的用于句子相似度计算的MPCNN模型仍然遵循Siamese network,模型使用CNN网络提取多粒度特征,配合多种pooling策略,在相似性计算层采用了多种计算方法,在以CNN构建的Siamese network模型上进行了创新。模型结构如下图所示: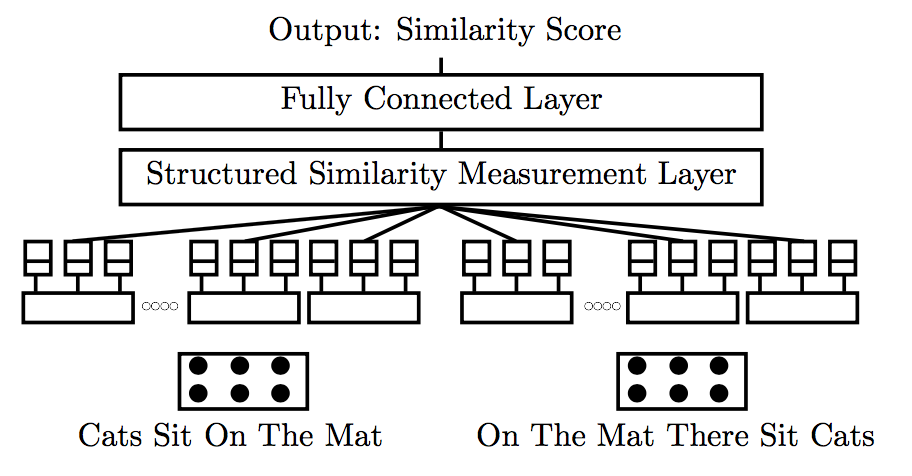
模型使用了两种卷积核,如下图所示: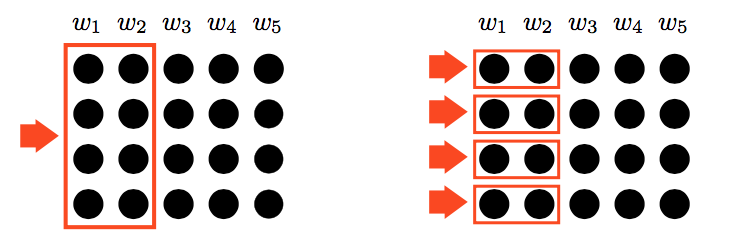
上图左边的卷积核即常用的卷积核,文中称为holistic filters。右边的卷积核限制了卷积的维度,对输入word embeddings各维度进行处理,文中称为per-dimension filters。
模型使用了三种pooling类型,分别为max-pooling, min-pooling和mean-pooling,并与上述两种filters进行组合,如下图所示: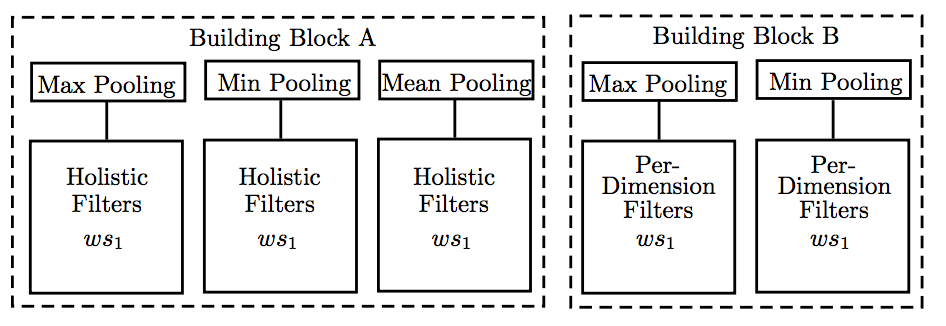
模型使用了大小不同的卷积窗口,并与上述两种filters和pooling类型进行组合,如下图所示: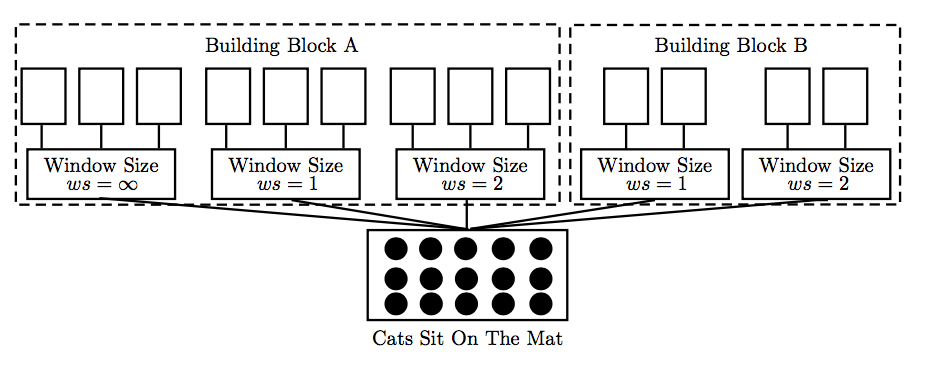
相似性计算层根据四个条件选择局部比较区域,分别是: 1) 是否来自同一个building block; 2)是否来自相同窗口大小的卷积层;3) 是否来自同一pooling层; 4) 是否来自卷积层中同一filter。当至少满足两个条件时进行相似性比较,相似性计算采用余弦相似度和欧式距离。该模型是基于CNN构建的Siamese network,采用了不同的卷积核,多种pooling策略等,模型比较复杂。
LSTM-BASED DEEP LEARNING MODELS FOR NON FACTOID ANSWER SELECTION
Ming Tan[4]于2016年发表的论文主要关注答案选择任务,文中提出了四个模型,其中前两个模型QA-LSTM,QA-LSTM/CNN属于Siamese network。QA-LSTM模型较为简单,利用双向LSTM分别处理Question和Answer,然后利用mean/max pooling获得Question和Answer的向量表示,利用两者的余弦相似度预测结果。QA-LSTM模型如下图所示: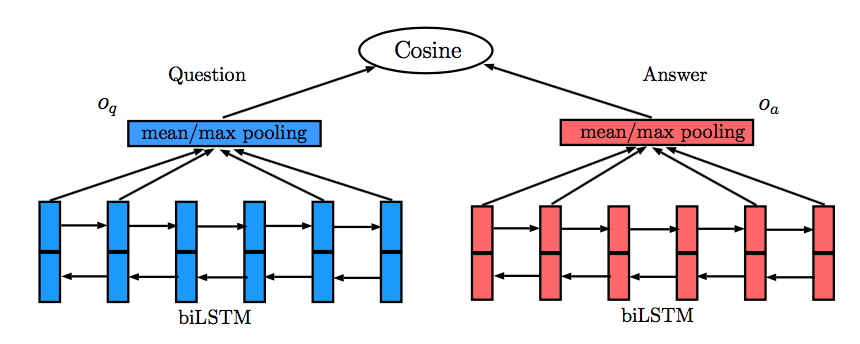
QA-LSTM/CNN模型为获得Question和Answer更多的组合表示信息,利用CNN对双向LSTM的输出进行处理,同样利用max-1 pooling产生Question和Answer对应的表示,然后利用余弦相似度预测结果,如下图所示: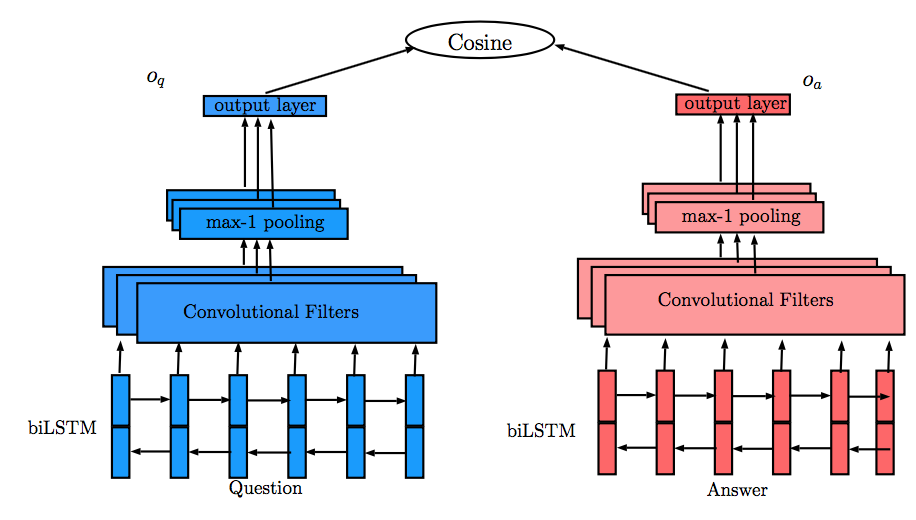
Learning to rank short text pairs with convolutional deep neural networks
Severyn A在对短文本对相似性排序一文[5]中使用了类似网络,与基本Siamese network相比略微有些变化。query和document中的单词首先通过word embedding处理后获得对应的表示矩阵,分别利用CNN网络进行处理获得各自的feature map,pooling后获得query对应的向量表示Xq和document的向量Xd。不同于传统的Siamese网络在这一步利用欧式距离或余弦距离直接对Xq和Xd进行相似性计算后预测结果,作者首先采用了一个相似矩阵来计算Xq和Xd的相似度,然后将Xd,Xq和sim(Xq,Xd)进行连接,并添加了word overlap和IDF word overlap的特征后作为特征向量输入一个神经网络层,神经网络层的输出经过一个全连接层,利用softmax函数得出预测结果。模型结构如下图所示: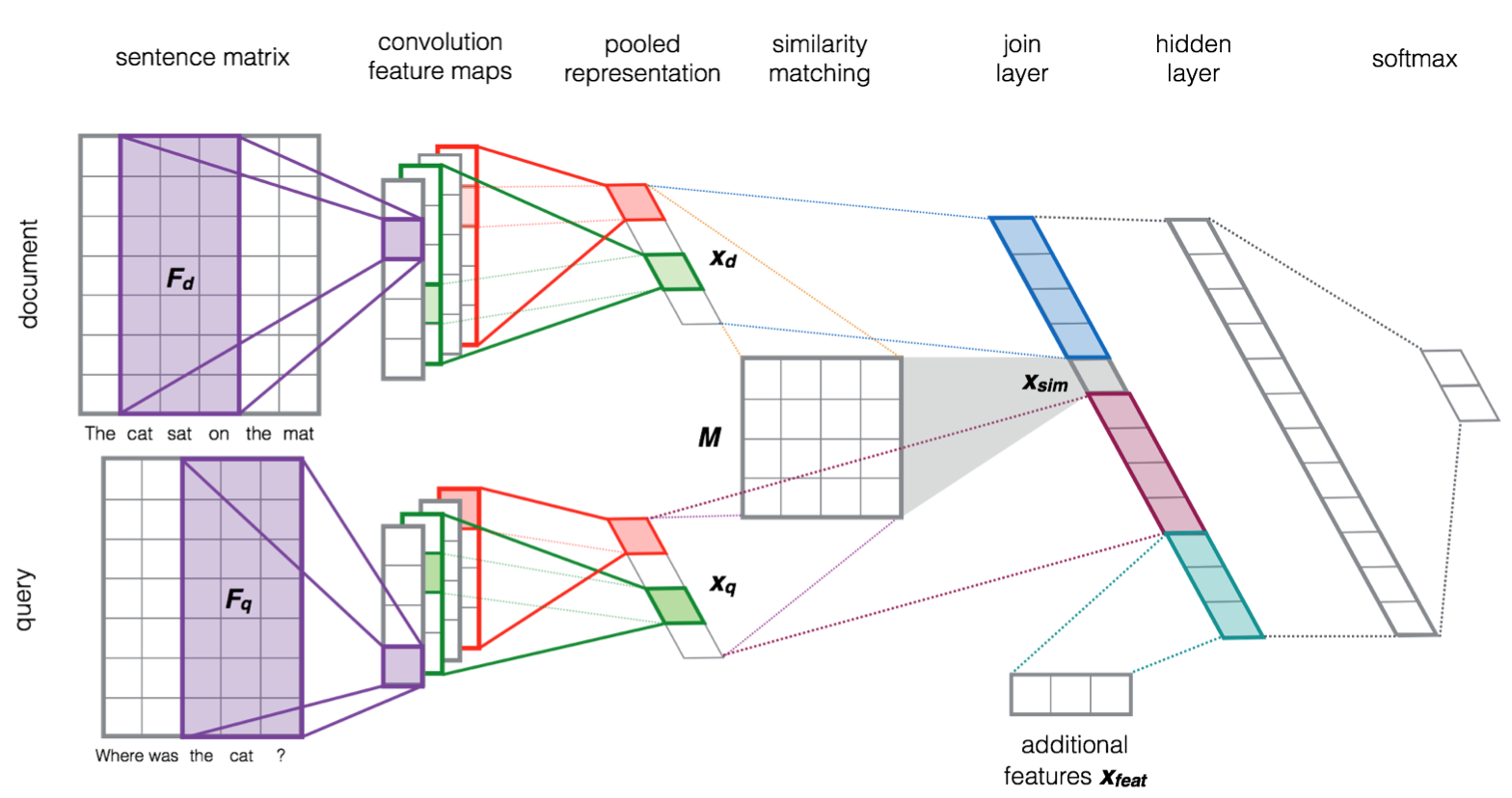
改进一 Attention Network
Siamese network单独处理输入的句子对,忽略了句子间的语义信息,通过引入注意力机制捕获句子间关联信息,用于相似性计算。注意力机制最早应用于视觉领域,2014年Bahdanau[4]在机器翻译任务中将翻译和对齐同时进行,在自然语言处理领域引入了注意力机制。
双向Attention Network
上文中已经提到,dos Santos[2]使用了Siamese网络作为Baseline,随后在Siamese网络的基础上引入了注意力机制,模型如下图所示: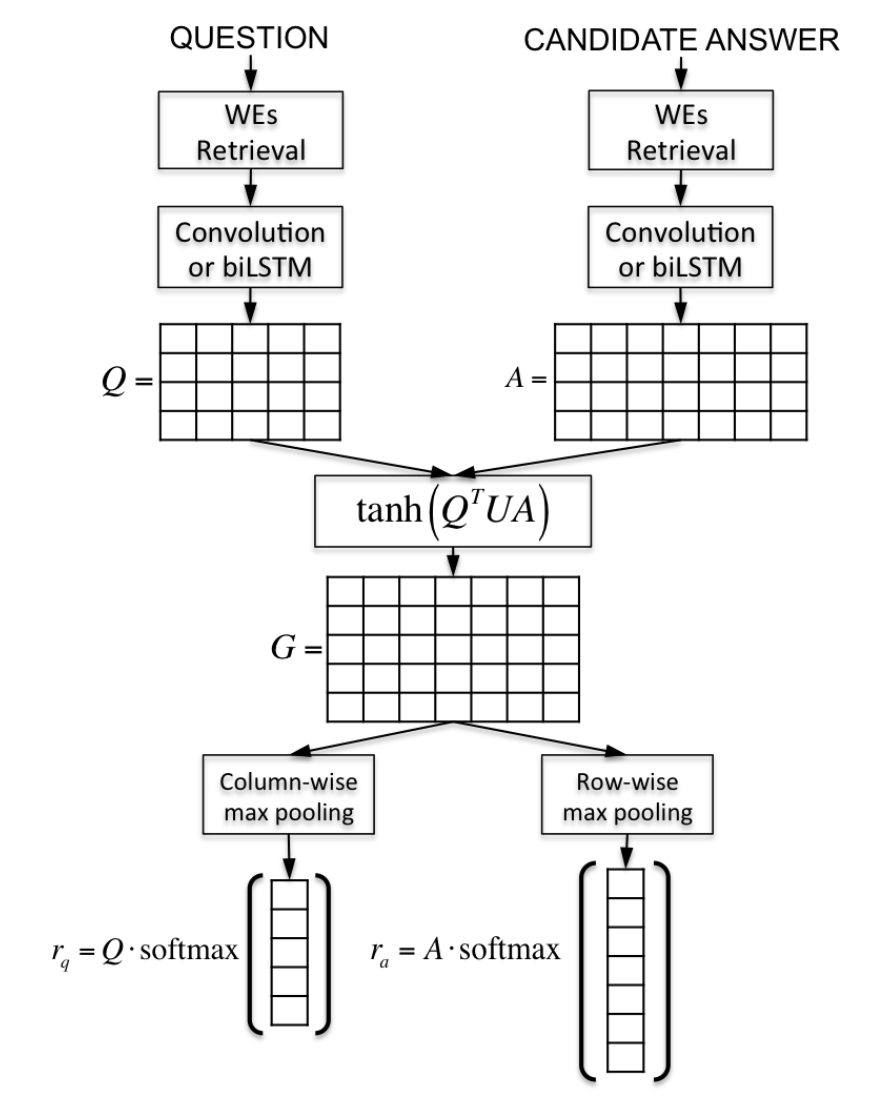
模型前期的处理与基本模型-Siamese network部分相同,在获得Question和Candidate answer的特征矩阵Q和A后,计算矩阵G:$G=tanh(Q^TUA)$。在矩阵G上应用Column-wise max pooling和Row-wise max pooling,并使用softmax函数处理后可分别获得Query和Candidate answer对应的注意力向量$\sigma ^{q}$和$\sigma ^{a}$,与Query矩阵和Answer矩阵对应相乘后获得Query向量$r_q$和Answer向量$r_a$,后续处理与基本模型Siamese network部分一致。
Attention-Based Convolutional Neural Network for Modeling Sentence Pairs
Yin W在其提出的ABCNN模型[7]中对Attention机制在CNN模型上的应用进行了更深入的探索,ABCNN模型主要解决句子对匹配问题。文中首先提出了BCNN基本模型,采用Siamese network结构,如下图所示: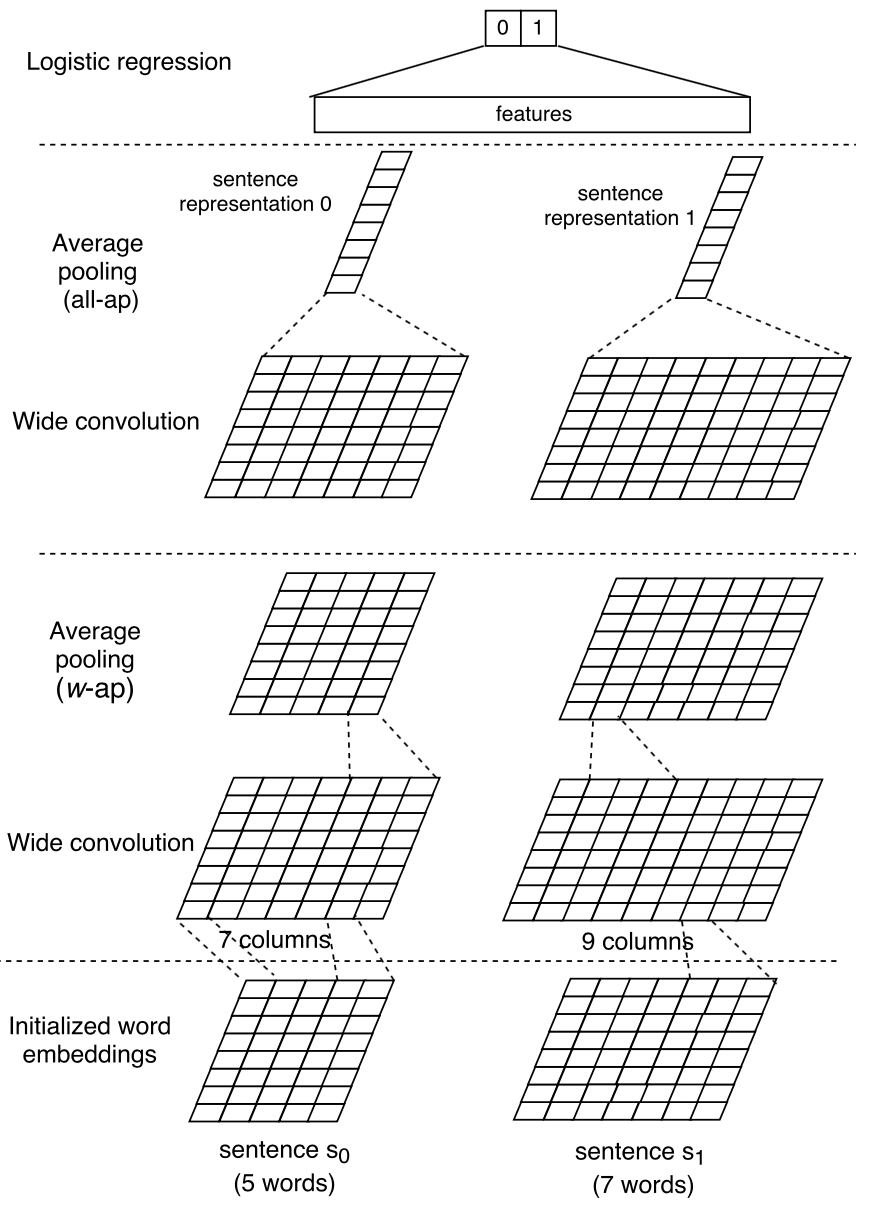
随后作者提出了ABCNN-1模型,如下图所示: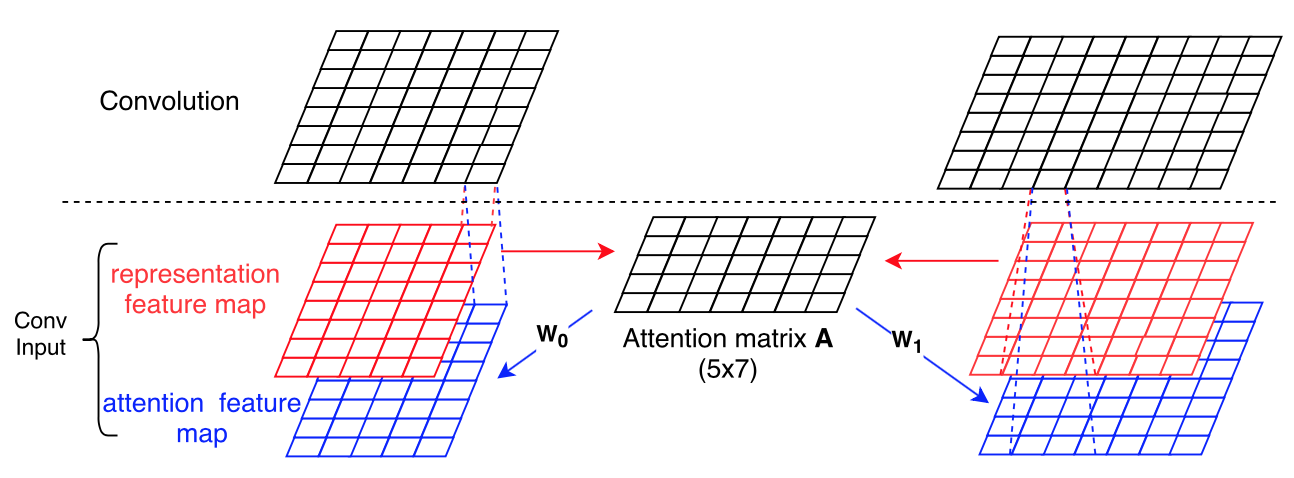
首先计算句子$S_0$和$S_1$的attention matrix A:$A_{i,j}=matchScore(F_{0,r}[:,i],F_{1,r}[:,j])$。$S_0$和$S_1$对应的representation feature map为$W_0$和$W_1$,将$W_0$和$W_1$与矩阵A相乘后可获得$S_0$和$S_1$对应的attention feature map。representation feature map和attention feature map输入CNN。
ABCNN-2模型则先利用CNN对representation feature map进行处理,如下图所示: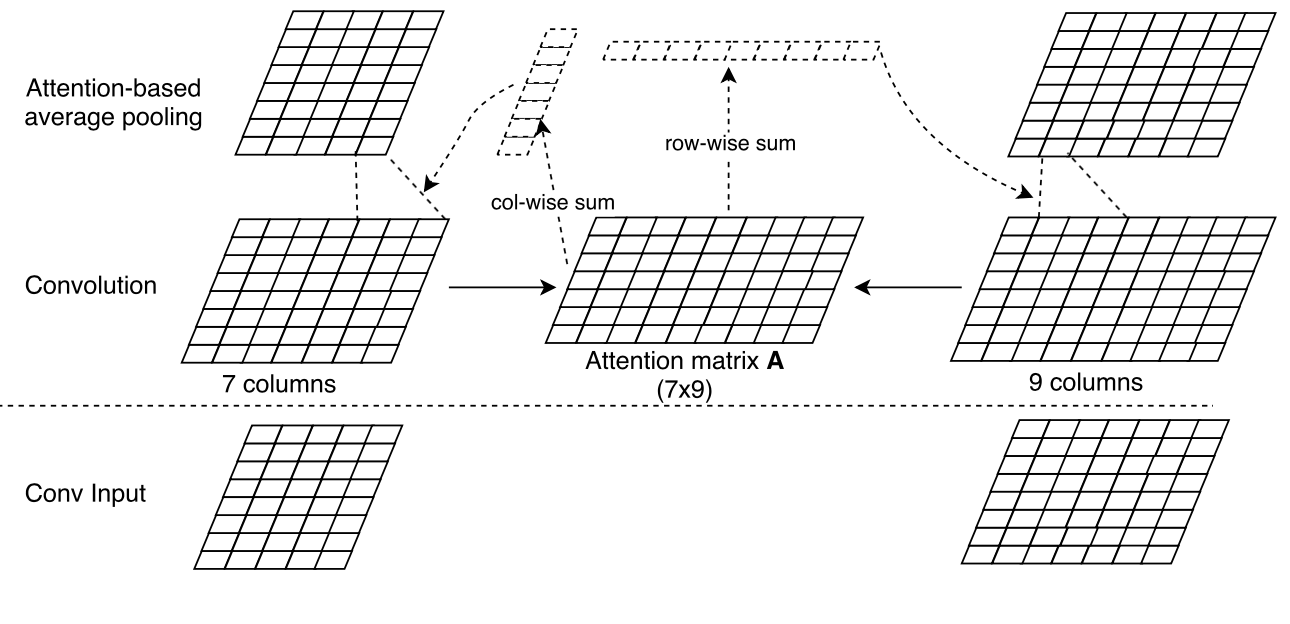
计算$S_0$和$S_1$经Convolution后的所得feature map的attention matrix A,在对Convolution feature map进行pooling处理时结合矩阵A,图中对应Attention-based average pooling部分。
ABCNN-1和ABCNN-2模型在不同粒度的语言单元上应用了Attention机制,ABCNN-3模型则将ABCNN-1和ABCNN-2模型进行了结合,旨在获得多粒度的特征,ABCNN-3模型如下图所示: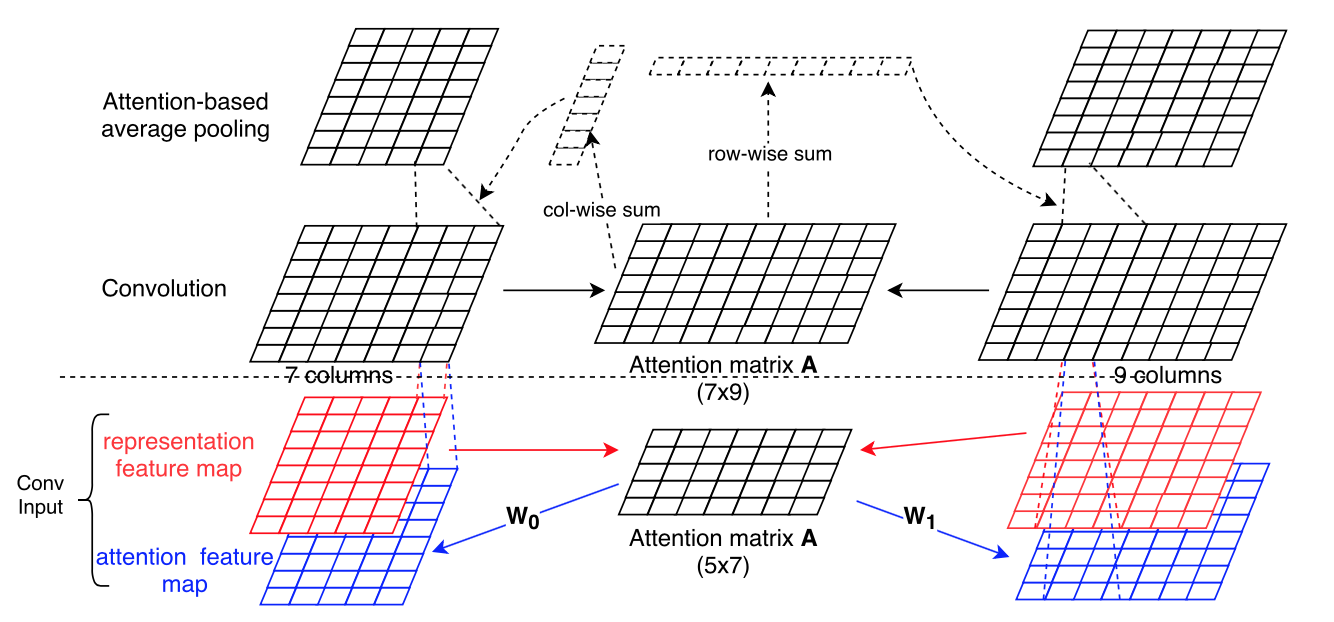
Attention-Based Multi-Perspective Convolutional Neural Networks for Textual Similarity Measurement
本篇论文[8]是基本模型部分介绍的MPCNN模型的改进,作者同样是Hua He。在MPCNN模型的基础上添加了Attention层,模型如下图所示:
设$S^{0}$和$S^{1}$分别表示两个句子,$S^{0}\left[ a\right]$表示$S^{0}$中第a个单词,$S^{1}\left[ b\right]$表示$S^{1}$中第b个单词,首先计算attention matrix D:$D[a][b]=cosine(S^0[a],S^1[b])$。获得矩阵D后,对矩阵按行/列求和,然后利用softmax获得句子对应的注意力权重向量,计算公式如下:
$$\begin{gather*}
E^0[a]=\sum _{b}D[a][b] \\
E^1[b]=\sum _{a}D[a][b] \\
A^i=softmax(E^i) \\
\end{gather*}$$
将单词原始embeddings和attention-reweighted embeddings进行连接后作为单词的表示输入Multi-perspective sentence model。文中并未使用常用的word2vec或GloVe模型,而是使用了PARAGRAM-PHRASE[9]对单词进行向量表示。
单向Attention Network
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION
Ming Tan[4]在基本模型部分介绍的QA-LSTM和QA-LSTM/CNN的基础上引入了Attention机制。ATTENTION-BASED QA-LSTM在QA-LSTM模型基础上进行了改进,如下图所示: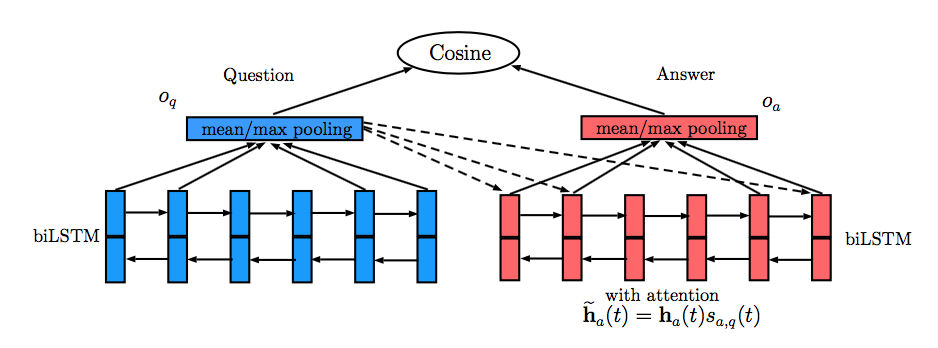
模型根据以下公式计算Answer的Attention表示:
$$\begin{gather*}
m_{a,q}(t) = tanh(W_{am}h_a(t)+W_{qm}o_q) \\
s_{a,q}(t) \propto exp(w_{ms}^Tm_{a,q}(t)) \\
\tilde{h_{a}}\left(t\right) = h_a(t)s_{a,q}(t) \\
\end{gather*}$$
其中$\tilde{h_{a}}\left(t\right)$表示经Attention处理后Answer中每个单词的表示。
经Attention处理后的Answer通过mean/max pooing获得Answer向量$o_a$,与Question向量$o_q$计算余弦相似度,预测结果。
QA-LSTM/CNN WITH ATTENTION对QA-LSTM/CNN的改进类似。
Inner Attention based Recurrent Neural Networks for Answer Selection
Bingning Wang[10]在发表于ACL 2016一文中改进了Attention的计算方式,用于解决QA中的答案选择问题。传统的Attention based RNN模型一般在RNN处理后再添加Attention信息,该文则在计算句子的表示前添加Attention信息,作者称为“Attention before representation”。文中首先给出了传统的attention based RNN模型,与3.3节介绍的ATTENTION-BASED QA-LSTM结构非常类似,可以参考3.3节内容。随后作者提出了四个“Inner Attention based Recurrent Neural Networks”模型,简称为IARNN。
IARNN-WORD
模型首先计算Question向量$r_q$与Candidate answer中各单词的注意力权重,并利用Attention结果更新单词向量,计算公式如下:
$$\begin{gather*}
\alpha_t = \sigma(r_q^TM_{qi}x_t) \\
\tilde {x}_{t} = \alpha_t * x_t \\
\end{gather*}$$
$\tilde {x}_{t}$表示更新后的单词向量,$r_q$代表Question向量。利用GRU处理$\tilde {x}_{t}$后进行average pooling作为Answer的表示,模型如下图所以: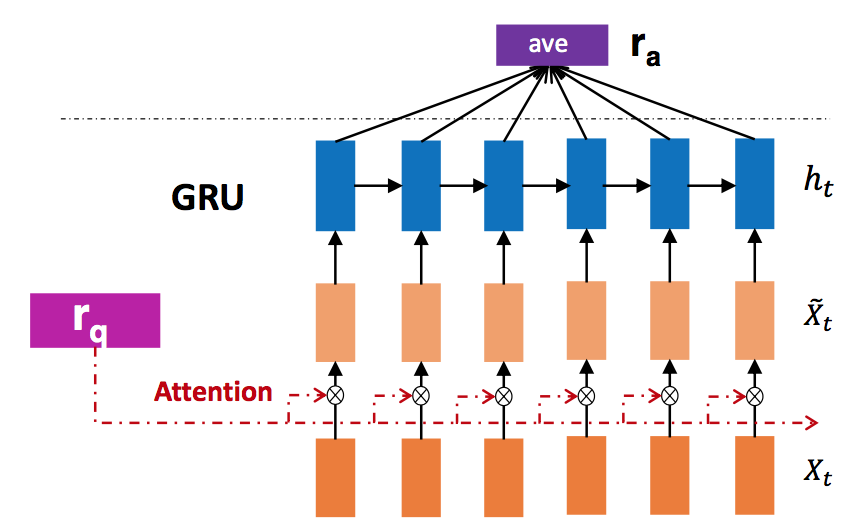
IARNN-CONTEXT
IARNN-WORD模型只是单独的处理每个单词,无法获得多个词间的联系,即一些上下文信息。IARNN-CONTEXT模型为了解决这一问题,在计算Attention时将$h_{t-1}$作为上下文信息加入,如下图所示:
$$\begin{gather*}
w_C(t) = M_{hc}h_{t-1} + M_{qc}r_q \\
\alpha_C^t = \sigma(w_C^T(t)x_t) \\
\tilde {x}_{t} = \alpha_C^t * x_t \\
\end{gather*}$$
IARNN-GATE
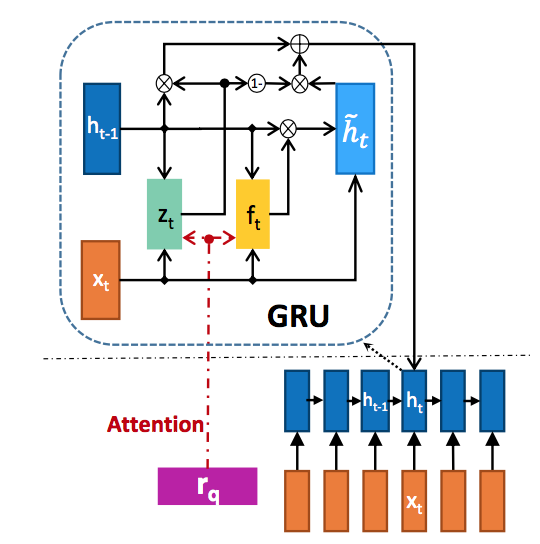
受到LSTM[]和利用主题信息建立单词表示[]的启发,作者将Attention应用到GRU内部的激活单元,上述IARNN-WORD和IARNN-CONTEXT是在单词原始表示上添加了Attention信息。因为GRU内部的激活单元控制了隐藏状态信息流,通过添加Attention信息可以影响隐藏表示,对原始GRU的改造如下图所示:
$$\begin{gather*}
z_t = \sigma(W_{xz}x_t + W_{hz}h_{t-1} + {\color{red} {M_{qz}r_q}}) \\
f_t = \sigma(W_{xf}x_t + W_{hf}h_{t-1} + {\color{red} {M_{qf}r_q}}) \\
\tilde {h}_{t} = tanh(W_{xh}x_t + W_{hh}(f_t \odot h_{t-1})) \\
h_t = (1-z_t) \odot h_{t-1} + z_t \odot \tilde {h}_{t} \\
\end{gather*}$$
IARNN-OCCAM
该模型的思想来源于Occam’s Razor,即:“Among the whole words set, we choose those with fewest number that can represent the sentence”。因为不同的问题对应的答案长度不同,例如When或者Who类型的问题的答案就相对较短,对应的正则数值应该大一点,而Why或How类型的问题答案较长,正则数字应该较小。文中利用下面的公式获得问题对应的正则系数,并加入目标函数$J_i$:
$$\begin{gather*} n_p^i = max\{w_{qp}^Tr_q^i,\lambda_q\} \\ J_i^* = J_i + n_p^i\sum _{t=1}^{mc}\alpha_t^i \\ \end{gather*}$$
其中$\gamma _{q}^{i}$代表问题$Q_i$对应的表示,$W_{ap}$用于将$\gamma _{q}^{i}$映射到一个标量,$\lambda _q$表示一个正超参数,$\alpha _{t}^{i}$表示注意力权重。
改进二 Compare-Aggregate Network
引入Attention机制后可以捕获句子间的语义信息用于相似性计算,改进一中的模型在获得句子经Attention处理后的特征后,一般会利用pooling对特征进行降维,这不可避免的会丢失一些信息,COMPARE-AGGREGATE Network为了解决这一问题,最后用于预测的特征不再是句子的表示特征,而是直接利用句子间的匹配特征用于预测,尽可能保留了句子间的相似性信息。
Pairwise Word Interaction Modeling with Deep Neural Networks for Semantic Similarity Measurement
Hua He在ACL 2016一文[11]中提出了一种“Pairwise Word Interaction”模型,旨在解决句子相似性计算问题,模型充分利用了单词级的细粒度信息。模型分为四个部分,分别为:Context Modeling、Pairwise Word Interaction Modeling simCube、Similarity Focus Layer focusCube和19-Layer Deep ConvNet,如下图所示: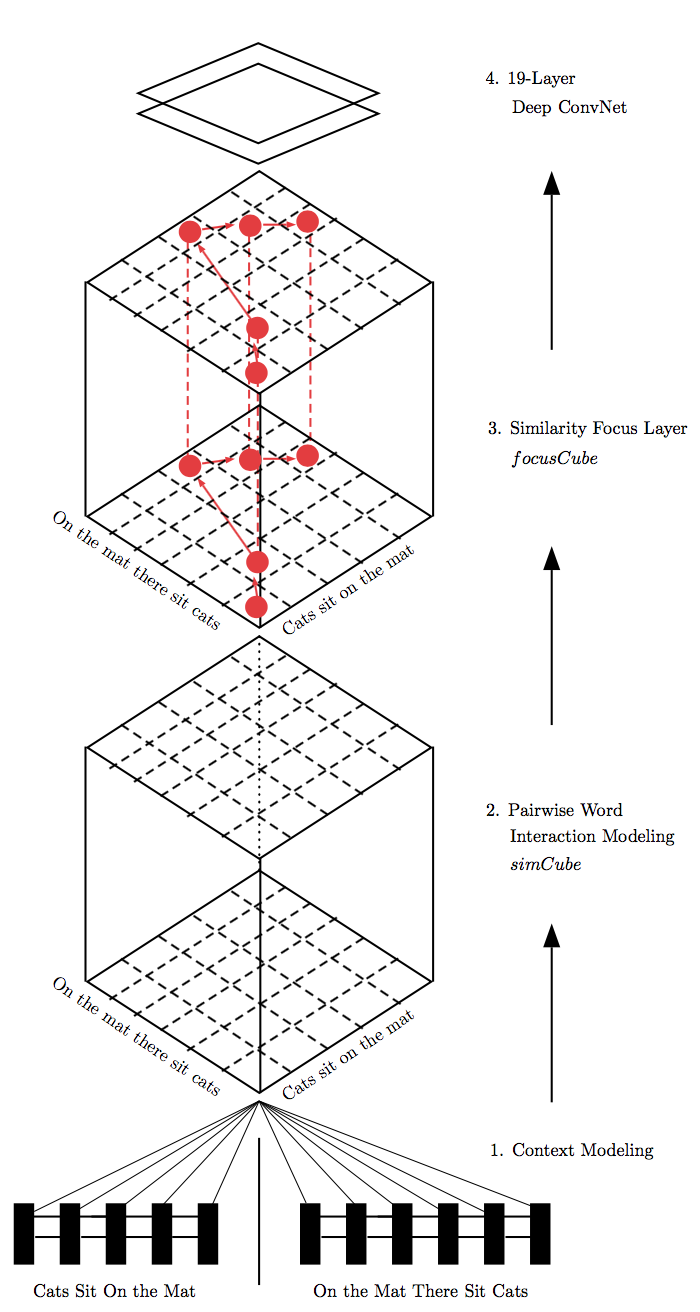
Context Modeling
首先对输入的句子单词进行Word embedding处理,然后利用BiLSTM获得句子中各单词包含上下文信息的表示。
Pairwise Word Interaction Modeling simCube
对句子$S_1$中BiLSTM的隐层状态$\overrightarrow {h_1}$与句子$S_2$的$\overrightarrow {h_2}$,模型使用下面的公式获得两者的匹配结果:
$$\begin{gather*}
coU(\overrightarrow {h}_{1},\overrightarrow {h}_{2}) = \{cos(\overrightarrow {h}_{1},\overrightarrow {h}_{2}),L_2Euclid(\overrightarrow {h}_{1},\overrightarrow {h}_{2}),DotProduct(\overrightarrow {h}_{1},\overrightarrow {h}_{2})\}
\end{gather*}$$
其中cos表示余弦距离,Euclid表示欧式距离。对句子$S_1$和句子$S_2$中每个单词进行匹配,获得句子间单词匹配结果simCube。在求取simCude时,作者使用了BiLSTM隐层状态的前向、后向、前后向拼接和前后向相加四种信息。
Similarity Focus Layer
在衡量句子间相似性时,不同的单词对相似性的影响不一样,本层识别对相对重要的单词对。首先按照simCube中相似性数值由大到小排序,然后使用一种标记算法(参考论文[]中的Algorithm 2)识别重要单词,并记录到mask矩阵。其中重要单词对的权重设为1,不重要单词对的权重设为0.1。最终的“focus-weighted similarity cube”由mask矩阵与simCube进行element-wise相乘后获得,记为focusCube。
19-Layer Deep ConvNet
focusCube可以看作是一个有13个通道的“图片”,因此相似性计算问题可以转换为识别图片中的“strong pairwise word”,即图片中“pairwise word interactions”越强,对应句子的相似度就越高。模型使用了CNN,配合Max pooling策略,最终由一个全连接层和lonSoftMax函数输出结果,模型比较复杂。
Bilateral Multi-Perspective Matching for Natural Language Sentences
Zhiguo Wang[12]针对自然语言句子匹配任务提出了bilateral multi-perspective matching (BiMPM) model,关于multi-perspective参见改进四部分,本节主要关注matching部分。设需要匹配的句子为P和Q,作者在P->Q,Q->P两个方向上进行了匹配,使用了四种匹配策略,这些策略可以理解为不同的Attention,这里也是Attention机制方面创新一个很好的参考。下面以P->Q方向为例进行说明,Q->P方向同理。
BiMPM模型如下图所示: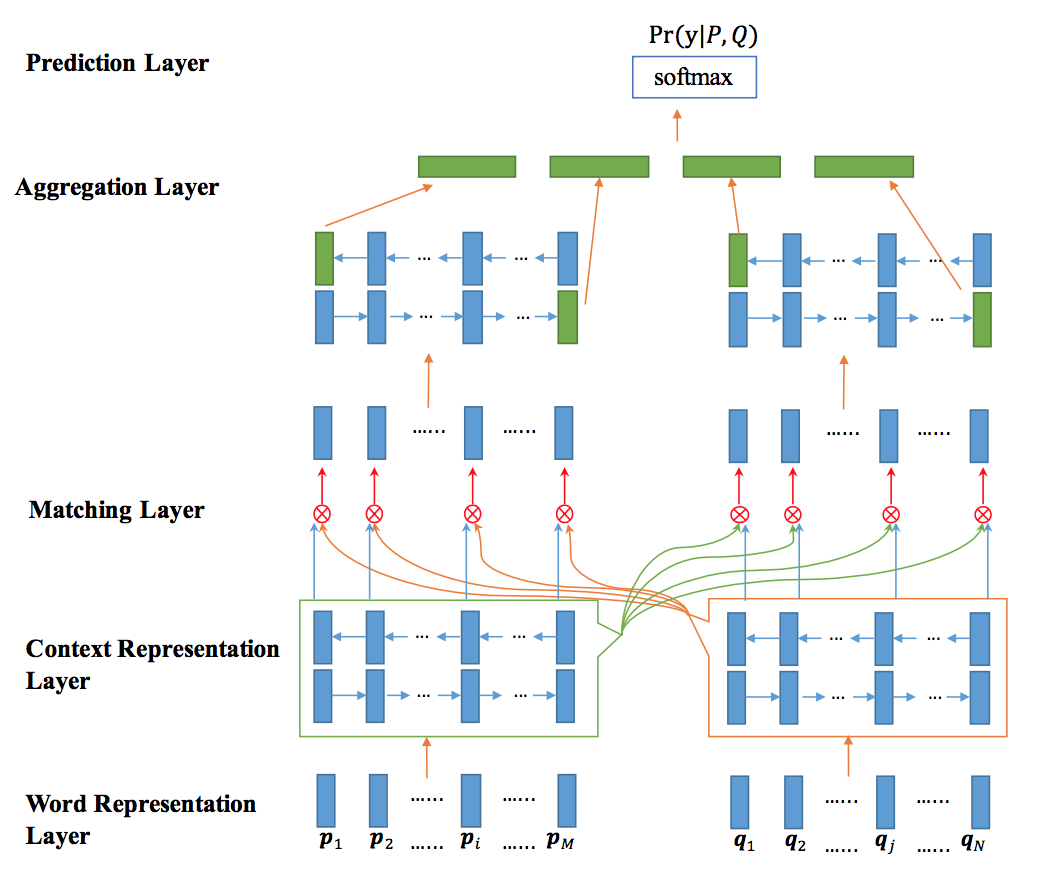
模型自下而上分为五层,分别为单词表示层、文法表示层、匹配层、聚合层和预测层,其中匹配层为模型的核心。单词表示层对单词进行Word embedding处理。文法表示层与聚合层类似,都是利用BiLSTM对输入序列进行处理。匹配层包含的四种匹配策略示意图: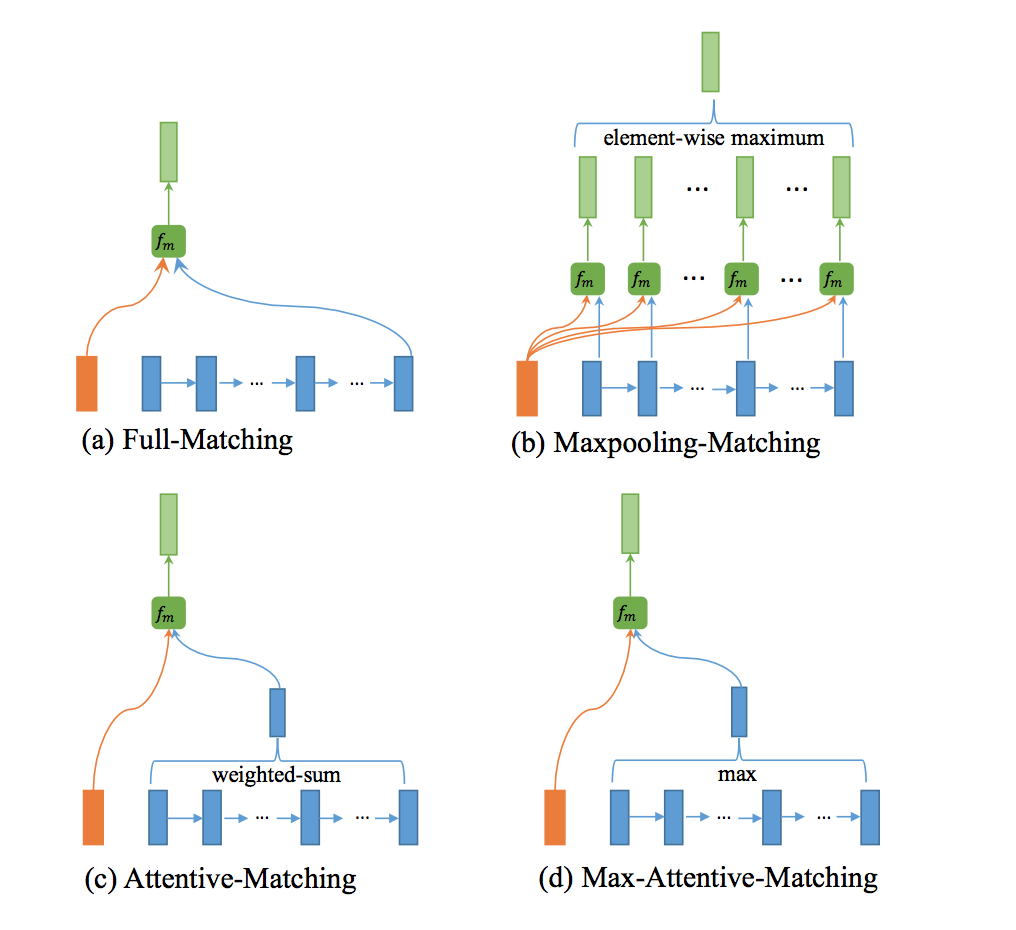
Full-Matching
P中每一个前向(反向)文法向量与Q前向(反向)的最后一个时间步的输出进行匹配。
Maxpooling-Matching
P中每一个前向(反向)文法向量与Q前向(反向)每一个时间步的输出进行匹配,最后仅保留匹配最大的结果向量。
Attentive-Matching
先计算P中每一个前向(反向)文法向量与Q中每一个前向(反向)文法向量的余弦相似度,然后利用余弦相似度作为权重对Q各个文法向量进行加权求平均作为Q的整体表示,最后P中每一个前向(后向)文法向量与Q对应的整体表示进行匹配。
Max-Attentive-Matching
与Attentive-Matching类似,不同的是不进行加权求和,而是直接取Q中余弦相似度最高的单词文法向量作为Q整体向量表示,与P中每一个前向(反向)文法向量进行匹配。
Matching Layer输出的匹配向量经Aggregation Layer双向LSTM处理后作为最后预测层的输入,预测层利用softmax函数输出预测结果。
A COMPARE-AGGREGATE MODEL FOR MATCHING TEXT SEQUENCES
本篇论文[13]依然关注自然语言句子匹配任务,模型充分体现了Compare-Aggregate网络的优点,主要在匹配方面进行了改进,使用了六种匹配函数,并对比了效果。上文介绍的BiMPM模型在Aggregation层利用双向LSTM对匹配向量进行处理,只取前(后)向最后的输出作为特征输入预测层。本篇论文没有使用RNN对匹配结果进行序列处理,而是采用CNN进行处理后用于最终的预测,模型如下图所示: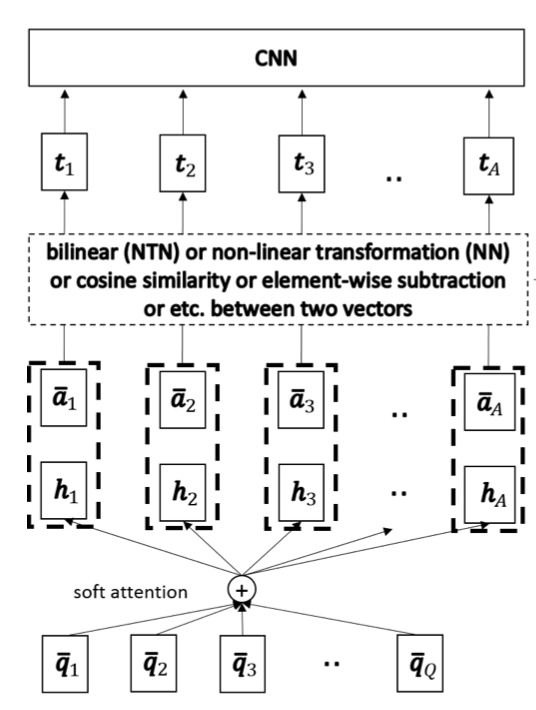
模型分为预处理层、Attention层、匹配层和聚合层,预处理层并未在图中进行说明,模型预处理与通常的模型一致,对Question和Answer进行Word Embedding处理,然后利用LSTM/GRU获得Question和Answer序列表示信息,这里作者进行了一些改变,仅保留了input gates。Attention层应用了单向Attention,对Question进行了Attention表示,具体计算公式如下:
$$G = softmax((W^g\overline {Q}) + b^g \otimes e_Q)^T \overline {A}) \\
H = \overline {Q}G$$
G表示注意力权重矩阵,H表示经Attention处理后的Question矩阵。匹配层在最后的“One more thing”部分会单独进行介绍,本节主要关注Compare-Aggregate模型。
One more thing
最后介绍两个在计算自然语言句子相似性时可能遇到的问题:1. 匹配时使用什么函数;2. 当多个句子相似程度较高时,如何利用句子中不相似的部分。
选择什么匹配函数
Wang S[13]在构建自然语言句子匹配模型时使用了六种匹配函数,如下图所示: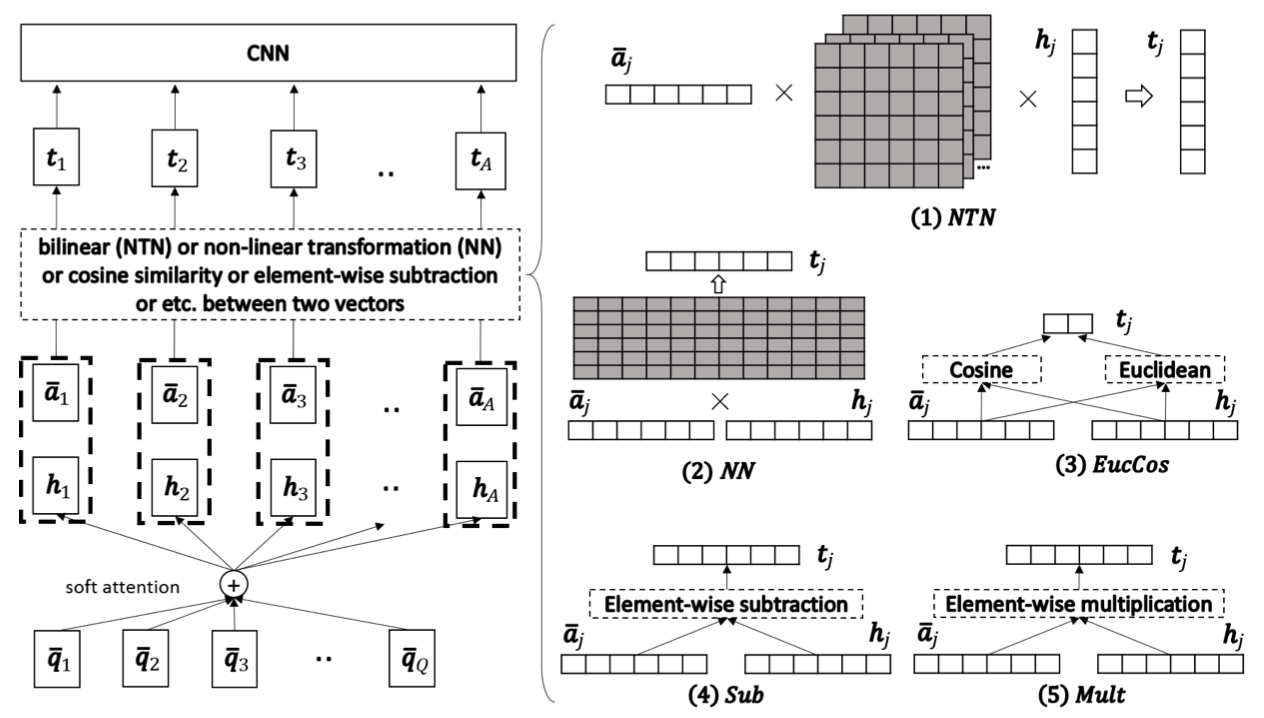
图中左半部分已在4.2节进行了介绍,右半部分属于模型的匹配层,包含了六种匹配函数,公式如下:
$t_j$表示匹配向量,f表示匹配函数,$\overline {a}_{j}$表示Answer中一个单词向量,$h_j$表示Question中一个单词向量。
NEURALNET (NN):
$$\begin{align}
t_j = f(\overline {a_j},h_j) = ReLU(W \left[ \begin{matrix} \overline {a}_{i}\\ h_{j}\end{matrix} \right] + b)
\end{align}$$
NEURALTENSORNET (NTN):
$$\begin{align}
t_j = f(\overline {a_j},h_j) = ReLU(\overline {a_{j}}^{T}T^{\left[ 1\ldots l\right]}h_j + b)
\end{align}$$
Euclidean distance ans Cosine similarity(EUCCOS):
$$t_j = f(\overline {a_j},h_j) = \begin{bmatrix}
\left | \left | \bar{a}_j - h_j \right | \right | _2 \\
cos(\bar{a}_j,h_j) \\
\end{bmatrix}$$
SUBTRACTION (SUB):
$$\begin{align}
t_j = f(\overline {a_j},h_j) = (\overline {a}_j - h_j) \odot (\overline {a}_j - h_j)
\end{align}$$
MULTIPLICATION (MULT):
$$\begin{align}
t_j = f(\overline {a_j},h_j) = \overline {a}_j \odot h_j
\end{align}$$
SUBMULT+NN
$$\begin{align}
t_j = f(\overline {a_j},h_j) = ReLU(W \left[ \begin{matrix} \left( \overline {a}_{j}-h_{j}\right) \odot \left( \overline {a}_{j}-h_{j}\right) \\ \overline {a}_{j}\odot h_{j}\end{matrix} \right] + b)
\end{align}$$
模型在四个数据集上进行了测试,结果如下图所示: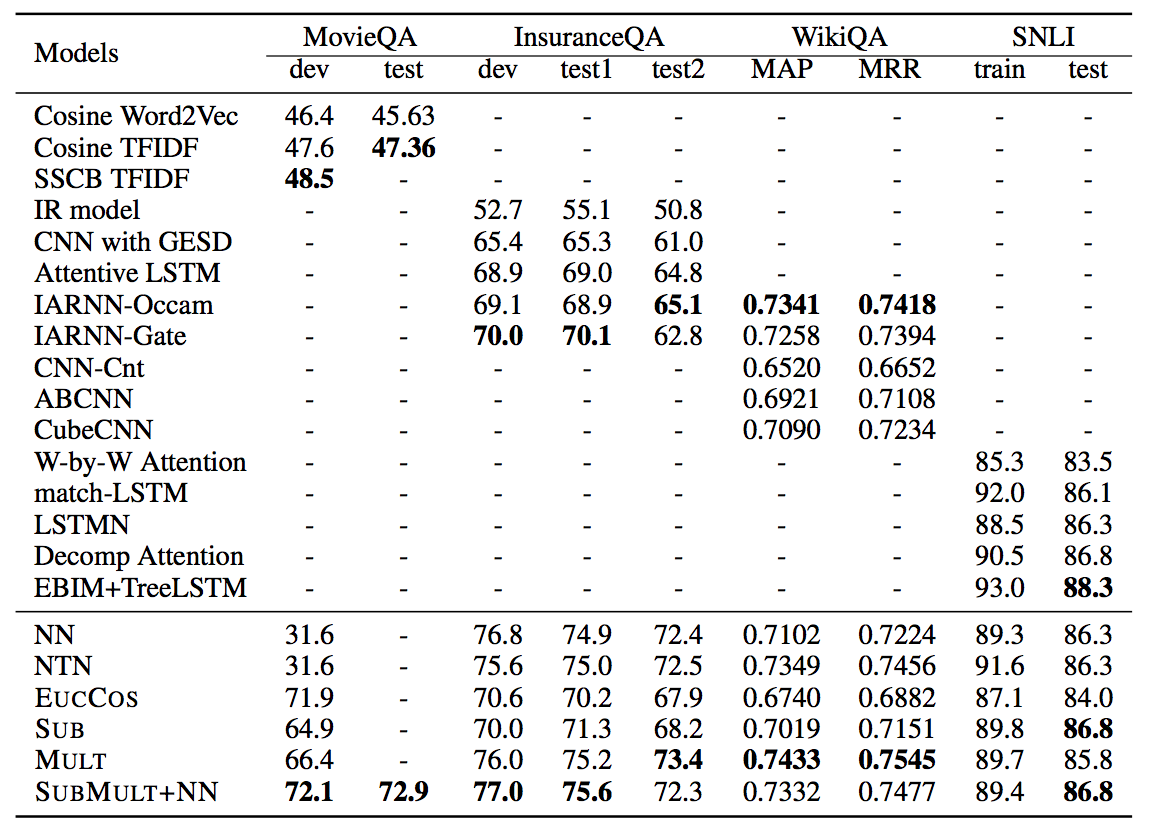
测试结果表明,一般情况下SUBMULT+NN性能较好。另一个值得注意的是一些简单的匹配函数在部分数据集上性能优于NN或NTN这些较为复杂的函数,例如MULT函数在WikiQA数据集上表现最好。
4.1节中介绍的BiMPM模型[12]中Multi-perspective也是对匹配函数进行了改进,使用了作者定义为“Multi-perspective cosine matching”的函数,公式如下:$m = f_m(v_1,v_2;W)$。其中$v_1$和$v_2$表示两个d维向量,W表示一个可训练参数,维度为[l,d],l表示perspectives数,函数$f_m$返回结果m为一个l维的向量:m=[$m_1$,…$m_k$,…,$m_l$],其中$m_k$代表第k个perspective的匹配结果:$m_k = cosine(W_k \circ v_1, W_k \circ v_2)$。o表示element-wise乘法,$W_k$表示W的第k行。
如何利用句子不相似的部分
Zhiguo Wang提出了一种“Lexical Decomposition and Composition”方法[14]用于解决句子相似性计算问题,本文简称为LDC,不同于一般模型主要关注相似的部分,作者通过对句子词法和语义信息进行分解和组合综合考虑了句子间相似和不相似的部分。模型在WikiQA数据集的测试结果达到了state-of-the-art水平,值得说明的一点是主要关注相似性部分的模型[BiMPM]在WikiQA数据集的测试结果要优于LDC模型,个人猜想与具体数据集特点有关,LDC模型更适合句子间相似度较高,需要利用不相似部分进行区分的数据集,例如文章中给出的例子,如下所示:
E1 The research is [irrelevant] to sockeye.
E2 The study is [not related] to salmon.
E3 The research is relevant to salmon.
E4 The study is relevant to sockeye, hinstead of cohoi.
E5 The study is relevant to sockeye, hrather than flounderi.
给定一个句子对S和T,模型计算相似度sim(S,T)。模型自下而上分为:Word Representation、Semantic Matching、Decomposition和Composition四个部分。Word Representation即使用预训练的word embeddings表示句子S和T。模型结构如下图所示: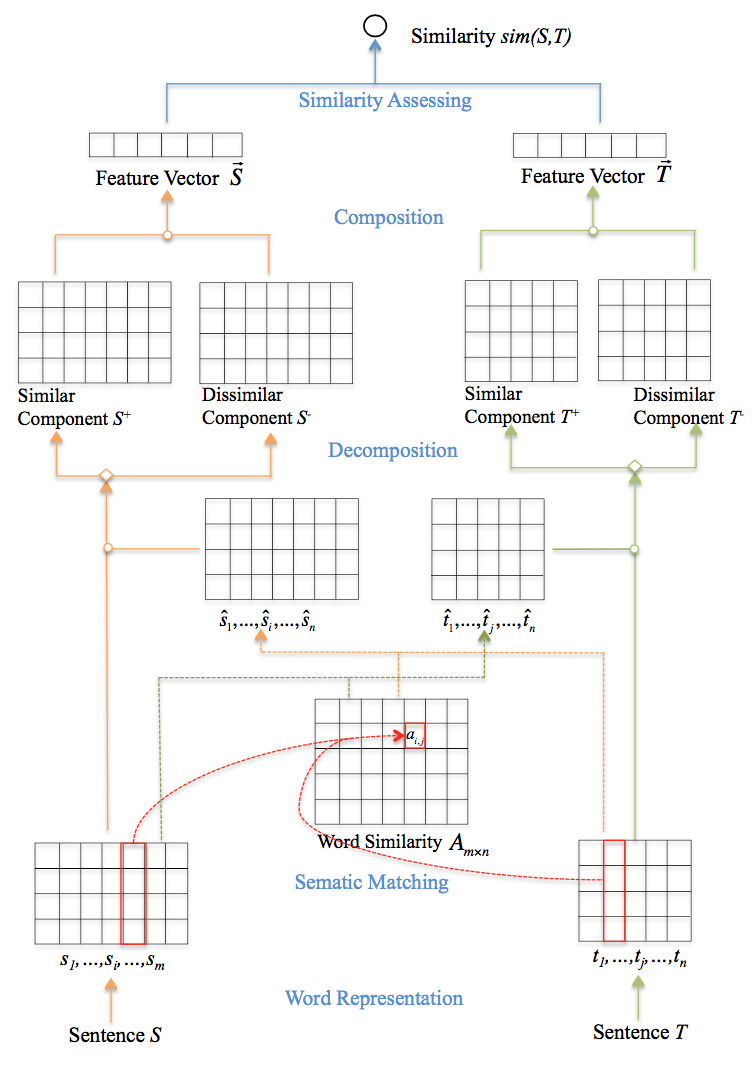
Semantic Matching
计算句子S中每个单词$s_i$与句子T的匹配向量$\widehat {s}_{i}$,同样也需要计算句子T每个单词的匹配向量$\widehat {t}_{i}$,公式如下:
$$\widehat {s}_{i} = f_{match}(s_i,T) \qquad \forall s_i\in S \\
\widehat {t}_{j} = f_{match}(t_j,S) \qquad \forall t_j\in T \\$$
对于一个句子对S和T,首先计算相似矩阵A,对于矩阵中的一个元素$a_{i,j}$,计算公式如下:
$a_{i,j}=\dfrac {S_{i}^{T} t_j} {\left| \left| s_i\right| \right| \cdot \left\| t_j\right\| } \qquad \forall s_i\in S,\forall t_j\in T$
获得相似矩阵A后,作者使用了三种匹配函数计算S和T的匹配向量,其中S匹配向量的计算公式如下(T计算公式同理):
$$\begin{align}
f_{match}(s_i,T) = \begin{cases} \dfrac {\Sigma _{j=0}^{n}a_{i,j}t_{j}} {\Sigma _{j=0}^{n}a_{i,j}} \qquad global \\ \dfrac {\Sigma _{j=k-w}^{k+w}a_{i,j}t_{j}} {\Sigma _{j=k-w}^{k+w}a_{i,j}} \qquad local-w\\ t_{k} \qquad max \end{cases}
\end{align}$$
其中$k=\arg \max _{j}a_{i,j}$,w表示local-w函数中以k为中心的窗口大小。
Decomposition
分解部分将句子S的匹配向量$s_i$分解为$s_{i}^{+}$和$s_{i}^{-}$两个部分,其中$s_{i}^{+}$表示相似部分,$s_{i}^{-}$表示不相似部分,句子T的分解方式同理,分解公式如下所示:
$$[s_i^+;s_i^-] = f_{decomp}(s_i,\widehat {s}_{i}) \qquad \forall s_{i}\in S \\
[t_j^+;t_j^-] = f_{decomp}(t_j,\widehat {t}_{j}) \qquad \forall t_{j}\in T$$
作者使用了三种分解函数,分别是:
rigid decomposition
$$[s_i^+ = s_i; s_i^- = 0] \qquad if s_i = \widehat {s}_{i} \\
[s_i^+ = 0; s_i^- = s_i] \qquad otherwise$$
linear decomposition
$$\alpha =\dfrac {s_{i}^{T}\widehat {s}_{i}} {\left| \left| s_{i}\right| \left| \cdot \right| \left| \widehat {s}_{i}\right| \right| } \\
s_i^+ = \alpha s_i \\
s_i^- = (1- \alpha)s_i\\$$
orthogonal decomposition
$$s_i^+ = \dfrac {s_{i} \cdot \widehat {s}_{i}} {\widehat {s}_{i} \cdot \widehat {s}_{i}} \widehat {s}_{i} \qquad parallel\\
s_i^- = s_i - s_i^+ \qquad perpendicular \\$$
Composition
组合部分利用CNN将相似部分$s_{i}^{+}$和不相似部$s_{i}^{-}$组合为最终S的特征向量$\overrightarrow {s}$,公式为:$c_{o,i} = f(w_o * S_{[i:i+h]}^+ + w_o * S_{[i:i+h]}^- + b_o)$。其中$w_o$表示CNN中的一系列filters,$S_{\left[ i:i+h\right] }^{+}$和$S_{\left[ i:i+h\right] }^{-}$表示$S^+$和$S^-$中的一部分。一个filter对$S^+$和$S^-$处理后会产生一系列特征$\overrightarrow {c_{o}}=[c_{o,1},c_{o,2},...,c_{o,O}$,利用max-pooling选择最大值,则全部的filters最终输出S和T对应的特征向量$\overrightarrow {S}$和$\overrightarrow {T}$。
Similarity assessing
计算S和T特征向量$\overrightarrow {S}$和$\overrightarrow {T}$的相似度:$sim(S,T) = f_{sim}(\overrightarrow {S},\overrightarrow {T})$,$f_{sim}$使用sigmod函数。
结论
WikiQA数据集测试结果
为方便的比较上述各模型,这里对各模型在WikiQA数据集上的实验结果(取最好)进行收集和整理,见下表:
| Model | MAP | MRR |
|---|---|---|
| CAM[13] | 0.743 | 0.754 |
| IARNN[10] | 0.734 | 0.741 |
| BiMPM[12] | 0.718 | 0.731 |
| PWIM[11] | 0.709 | 0.723 |
| LDC[14] | 0.705 | 0.722 |
| ABCNN[7] | 0.692 | 0.712 |
| APN[2] | 0.688 | 0.695 |
表中ABCNN、APN和LDC模型属于Attention Network,CAM、IARNN、BiMPM和PWIM模型属于Compare-Aggregate Network。WikiQA数据集上的实验结果表明Compare-Aggregate Network优于Attention Network。
结果分析
基本模型Siamese Network单独的对两个输入句子进行特征提取,Attention Network除了获得两个句子各自特征外,还使用句子间的相关特征。Attention Network依然遵循Siamese Network思想,一般将句子表示为一个特征向量用于预测,最后的降维过程不可避免的损失一些相关性信息,Compare-Aggregate Network则直接利用句子间相关特征进行预测。模型的测试结果表明,在计算句子相似度时,如何有效的利用句子间的相关特征是模型的关键。
各模型针对的问题及解决方法
| Model | 问题 | 解决方案 |
|---|---|---|
| APN[2] | 基本模型无法获得两路输入的联合表示 | 双向Attention |
| MPCNN[3] | 语言表达的多样性、歧义 | 利用CNN提取不同粒度特征,配合多种pooling策略,在不同句子区域使用多种函数进行比较 |
| LBDLM[4] | 句子在词级别不相似,但在语义级别相似;LSTM输出直接进行pooling可能会损失语言区域信息 | 利用CNN对LSTM输出进行处理,获得问题和答案更多的组合表示信息 |
| LRCNN[5] | 传统特征工程需要复杂的工作和额外资源 | 词向量, CNN |
| ABCNN[7] | 基本模型单独处理两个句子,没有充分考虑句子间的联系 | 双向Attention |
| ABMPCNN[8] | MPCNN无法获得句子间信息 | 改进MPCNN模型,加入Attention层 |
| IARNN[10] | 传统的Attention-based RNN模型使用“Attention after represention”,在生成单词表示时存在不足 | “Attention before represention”,在使用LSTM处理之前进行Attention |
| PWIM[11] | 一般的神经网络模型主要利用句子粗粒度信息,无法捕获细粒度词级别的信息 | pairwise word interaction modeling,捕获跨句子的词关联信息 |
| BiMPM[12] | 传统的模型只在一个方向上应用Attention,匹配时只在词级别或句子级别进行匹配 | 双向Attention,multi-perspective匹配函数,四种匹配策略 |
| CAM[13] | 选择什么匹配函数 | 对比六种匹配函数在四个数据集的结果,选择SUBMULT+NN或MULT |
| LDC[14] | 当要比较的句子结构非常相似时,如何利用不相似的部分进行区分 | Lexical Decomposition and Composition |
各模型损失函数及额外特征选取
注:部分论文针对不同的数据集使用了相应的损失函数。
| Model | 损失函数 | 额外特征 |
|---|---|---|
| APN[2] | hinge loss | 未使用 |
| MPCNN[3] | hinge loss, KL-divergence loss | PARAGRAM vectors, POS tagger |
| LBDLM[4] | hinge loss | 未使用 |
| LRCNN[5] | cross-entropy | 不明确,论文中给出了添加Addition features的方法 |
| ABCNN[7] | 不明确 | sentence lengths, WordCnt and WgtWordCnt |
| ABMPCNN[8] | 不明确 | PARAGRAM-PHRASE word embeddings |
| IARNN[10] | max-margin hinge loss | 未使用 |
| PWIM[11] | hinge loss, KL-divergence | 未使用 |
| BiMPM[12] | Cross-Entropy | 未使用,但可扩展使用POS,NER特征 |
| CAM[13] | 不明确 | 未使用 |
| LDC[14] | 不明确 | 未使用 |
本文中错误和不明确之处欢迎指出,谢谢!
引用:
[1] Bromley J, Guyon I, LeCun Y, et al. Signature verification using a” siamese” time delay neural network[C]//Advances in Neural Information Processing Systems. 1994: 737-744.
[2] dos Santos C N, Tan M, Xiang B, et al. Attentive pooling networks[J]. CoRR, abs/1602.03609, 2016.
[3] He H, Gimpel K, Lin J J. Multi-Perspective Sentence Similarity Modeling with Convolutional Neural Networks[C]//EMNLP. 2015: 1576-1586.
[4] Tan M, Santos C, Xiang B, et al. Lstm-based deep learning models for non-factoid answer selection[J]. arXiv preprint arXiv:1511.04108, 2015.
[5] Severyn A, Moschitti A. Learning to rank short text pairs with convolutional deep neural networks[C]//Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2015: 373-382.
[6] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[7] Yin W, Schütze H, Xiang B, et al. Abcnn: Attention-based convolutional neural network for modeling sentence pairs[J]. arXiv preprint arXiv:1512.05193, 2015.
[8] He H, Wieting J, Gimpel K, et al. UMD-TTIC-UW at SemEval-2016 Task 1: Attention-Based Multi-Perspective Convolutional Neural Networks for Textual Similarity Measurement[C]//SemEval@ NAACL-HLT. 2016: 1103-1108.
[9] Wieting J, Bansal M, Gimpel K, et al. Towards universal paraphrastic sentence embeddings[J]. arXiv preprint arXiv:1511.08198, 2015.
[10] Wang B, Liu K, Zhao J. Inner Attention based Recurrent Neural Networks for Answer Selection[C]//ACL (1). 2016.
[11] He H, Lin J J. Pairwise Word Interaction Modeling with Deep Neural Networks for Semantic Similarity Measurement[C]//HLT-NAACL. 2016: 937-948.
[12] Wang Z, Hamza W, Florian R. Bilateral multi-perspective matching for natural language sentences[J]. arXiv preprint arXiv:1702.03814, 2017.
[13] Wang S, Jiang J. A Compare-Aggregate Model for Matching Text Sequences[J]. arXiv preprint arXiv:1611.01747, 2016.
[14] Wang Z, Mi H, Ittycheriah A. Sentence similarity learning by lexical decomposition and composition[J]. arXiv preprint arXiv:1602.07019, 2016.