目前知识图谱问答主流方法有基于语义解析、信息抽取和向量建模三种,近些年来流行的深度学习技术主要在向量建模方面进行改进。截止2016年,在公开数据集WebQuestion上表现最好的模型主要是对语义解析进行了改进,将问题转换为查询图,并利用CNN进行特征提取和相似性计算。
注:本文中的图片均引用自相关论文和资料。
语义解析
语义解析的主要方法是将自然语言句子转化为逻辑语句,然后通过数据库查询得到答案,Jonathan Berant[1]发表于EMNLP 2014的文章是一个典型例子。下面以一个具体问题为例子,简述一下整体过程。给定一个自然语言的问题:
“Where was Obama born?”
语义解析树
首先利用语义解析工具对问题进行解析,如下图所示: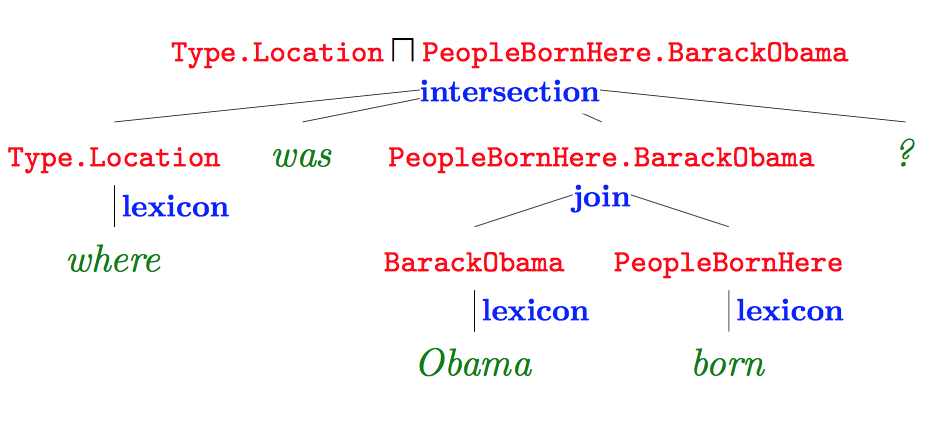
图中红色部分为逻辑形式,绿色部分为原始问题,蓝色部分表示词汇映射和构建对应的操作,语义解析树根节点即为解析结果。
模型的训练主要是针对每一种语义解析结果的分类概率,对于训练数据问题-答案对,通过最大化log-likelihood损失函数,利用随机梯度下降对参数进行更新。
实验结果
KBQA常用的数据集是WebQuestion,包含5810组问题-答案对,该文章的方法在WQ数据集上达到了32.9%的正确率。
该文章开放了语义解析器Sempre。
信息抽取
信息抽取的方法首先提取问题中的实体,然后在知识库中查找该实体以及以该实体节点为中心的知识库子图,候选答案则从子图中的节点或边获得。而具体答案的选择则需使用规则或模版进行抽取,同时利用问题和候选答案的特征,建立分类模型,通过候选答案的特征进行筛选,最终得到答案。
本部分以X Yao[2]发表于2014年ACL会议的文章为例,简述基于信息抽取方法的知识图谱问答过程。仍以一个具体问题为线索,例如:
“what is the name of Justin Bieber brother?”
获得语法依存树
首先获得句子的语法依存树(Dependency Tree),如下图所示: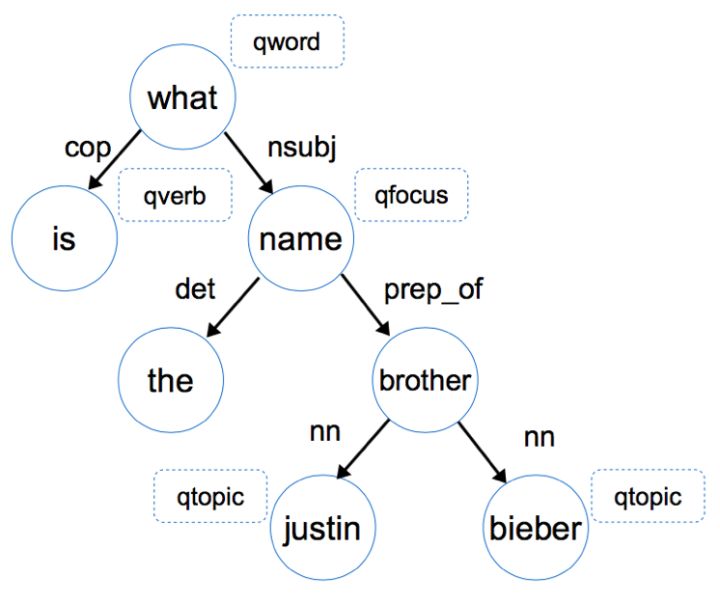
通过依存关系推理得到答案的类型,本例中答案是一个人名。在确定答案类型后,便可以在候选答案中进行筛选和选择。
本文首先提取问题中的问题词(qword),例如Who, When和Where这样的疑问词,对于上文给出的具体问题,问题词为”What”。然后确定问题焦点(qfocus),焦点词可以指示答案类型,例如name, time和price等。接着抽取问句的主题词(qtopic),主题词用于在知识库中进行查找,本例中的主题词为“Justin Bieber”。最后是提取问句中的中心动词(qverb),例如当中心动词为“eat”时,可以判断答案可能是某种食物。
依存树转化为问题图
通过问题词qword、问题焦点qfocus、问题主题词qtopic和问题中心动词qverb四个特征,可以将问题依存图转化为问题图: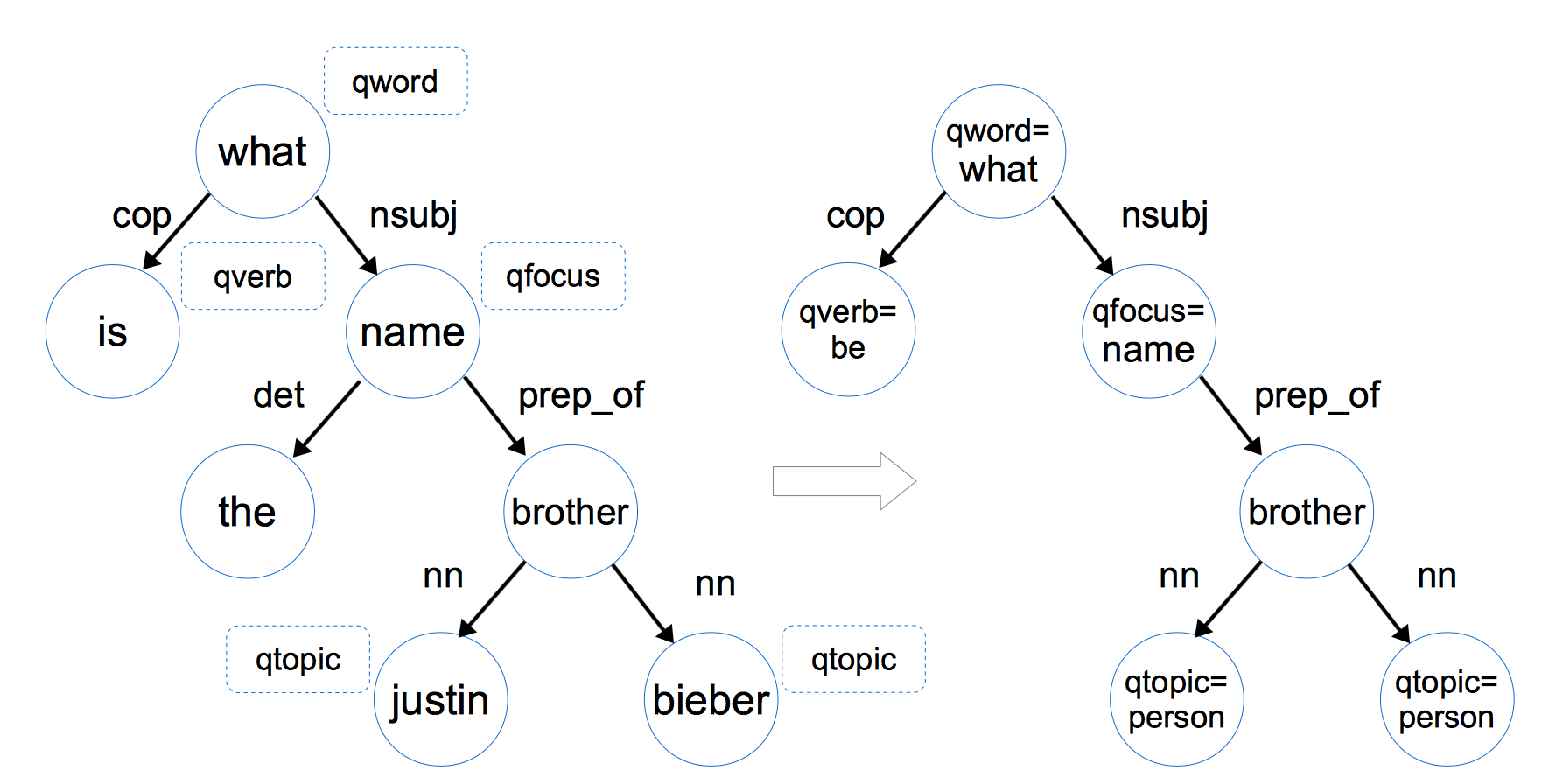
依存图包含了问题全部的信息,通过对问题进行信息抽取,转化为问题图,提取出对于查找答案的主要特征,删去不重要的信息。
获得问题图后,下面便是基于知识库进行查找和选择答案,选择答案可以看作一个二分类问题,即判断候选答案是否为正确答案。通过问题-答案数据,训练一个分类器模型,常用的有SVM,MLP和LR等,本文采用的是带L1正则化的逻辑回归。
特征选择
分类模型确定后,下面就是选择特征。本文选择了三类特征,分别是问题特征、候选答案特征和问题-候选答案关联特征。问题特征基于问题图抽取,候选答案特征则基于知识图谱信息抽取,包括节点的关系和属性,如下图所示: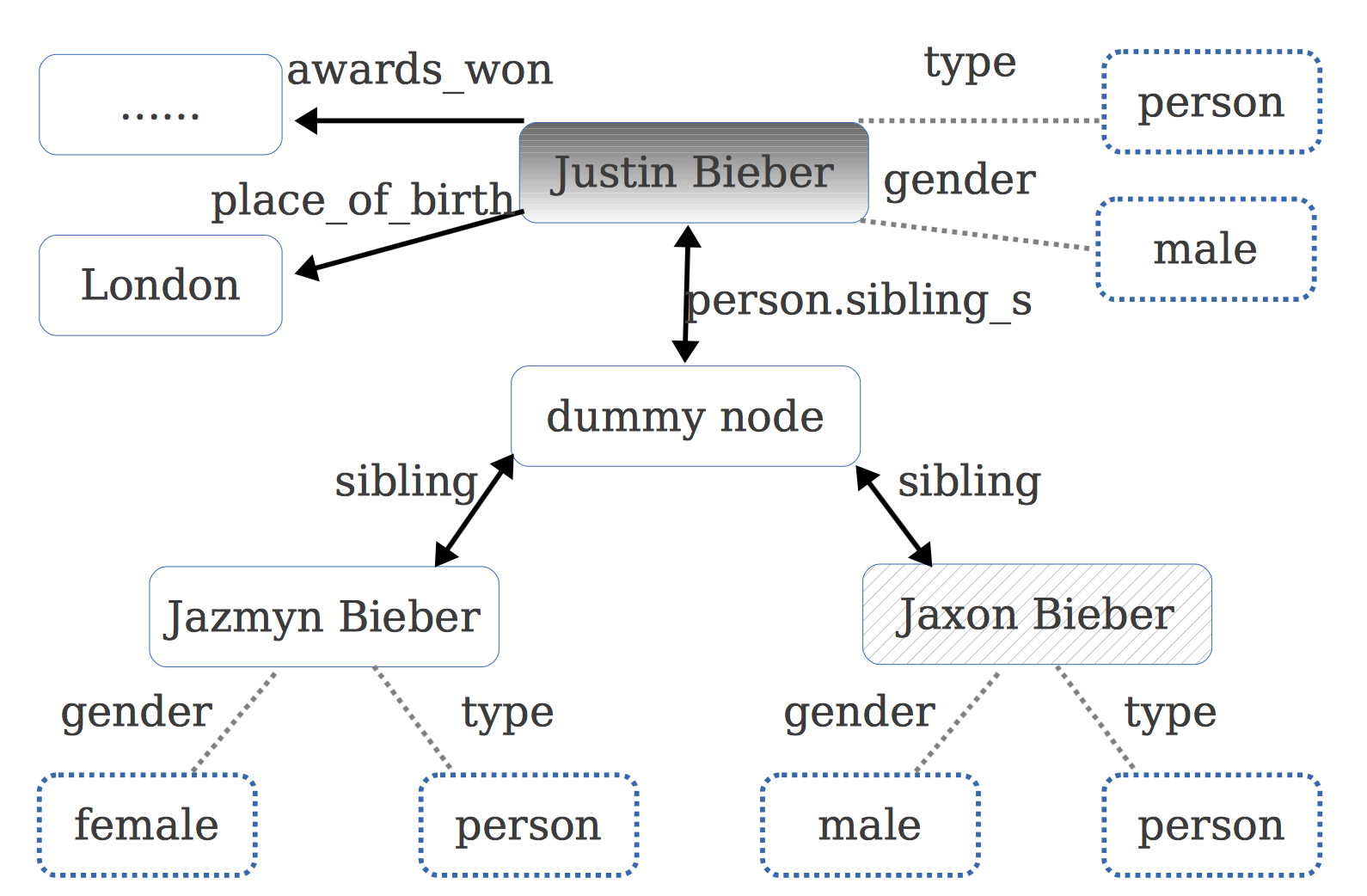
例如对于“Justin Bieber”这个qtopic节点,可以提取出gender=male,type=person等信息。知识图谱中的这些结构化的特征信息,对于选择正确答案提供了很大帮助。
问题-候选答案联合特征通过对问题中的特征和答案的特征进行组合获得,并且关联度较高的特征具有更高的权重。例如当问题的焦点词qfocus=price时,node type=number会比node type=person的关联特征权重高。
实验结果
相比Jonathan Berant[1]的方法,本文在WebQuestion数据集上的F1-score达到了42.0%,有了较大提升。
向量建模
one-hot&multi-hot表示方法
信息抽取方法中的特征,解释性较高,但涉及较多的语言学知识和人工构造的规则。向量建模的方法则利用分布式表达来构造问题和答案的特征,而深度学习技术也主要在这里进行提升。本部分首先以Antoine Bordes[3]等人在EMNLP 2014中发表的文章为例,简述如何利用向量建模的方法实现KBQA。
向量建模的方法与信息抽取思想类似,首先抽取问句中的主题词,根据主题词在知识库中搜索候选答案,不同于知识抽取中解释性较高的词法、属性等特征,向量建模方法将问题和候选答案映射到一个低维空间,得到其分布式表达,然后通过对该分布式表达进行训练,最大化问题向量与其对应正确答案的得分。模型训练完毕后,利用问题向量与候选答案向量的得分选择答案,得分最高的即为正确答案。
分布式表达
问题:输入空间的维度N = 字典大小+知识库实体数目 + 知识库实体关系数目。问题向量将对应维度代表的单词设置为在问题中出现的次数,其余为0.
答案:答案的向量化有三种方法。
- 类似问题的方式,由于知识库中的实体唯一,因此答案可以表达为one-hot形式。
- 加入知识库中与主题词相关的实体和实体关系信息。通过问题中的主题词可以定位到知识图谱中的某个节点,将该节点到答案节点路径上的边(实体关系)和点(实体)都以multi-hot形式作为答案的输入向量。
- 加入知识库中候选答案节点的属性和关系信息。通过主题词定位节点后,将候选答案对应的知识库子图(1跳或两跳范围)信息也加入答案向量。
向量得分
问题向量与答案向量点乘。
整体流程如下图所示: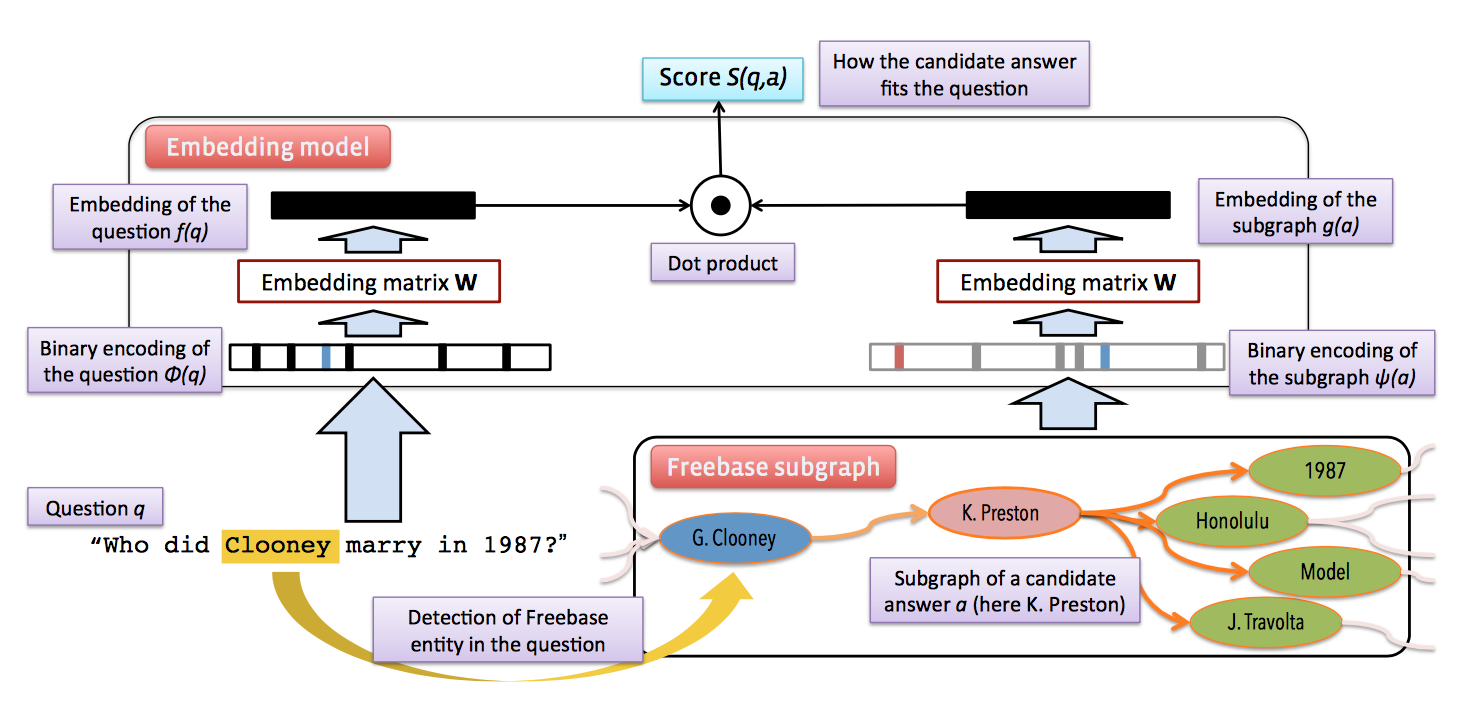
训练分布式表达
构造正负样本,利用margin-based ranking损失函数,即hinge loss,进行训练。向量建模方法的一个缺点是在获得文本的分布式表达时需要较大的训练数据,因此作者除了WebQuestion外,还利用了Freebase和Wiki数据。
实验结果
在WebQuestion数据集上F1-Score为39.2。
小结
向量建模的方法,可解释性不如语义解析和信息抽取,语义解析将问题转化为一种逻辑表达形式,信息抽取中利用的特征也是可见的,但不需要人工去定义许多特征,也不需要词汇映射表、依存解析等外部资源,实现过程相对简洁。
深度学习
近些年来流行的深度学习技术在KBQA领域也得到了广泛应用,例如CNN, RNN, Attention和Memory Network。本部分以2015年 ACL会议的Outstanding Paper为例,对深度学习技术在KBQA的应用进行简单介绍。Wen-tau Yih[4]等主要利用深度学习在语义解析方面进行了改进,针对传统方法的不足,将语义解析过程转化成查询图分阶段生成的过程,利用CNN获得自然语言到知识库的映射。截止2016年,该方法在WebQuestion取得了最好的效果。
传统语义解析方法的缺点
传统方法一般时先将自然语言转化为逻辑形式,然后将逻辑形式转化为查询语句,最终在知识库中查找得到答案。生成逻辑形式的过程主要基于问句中的信息和语法解析器,几乎没有使用知识库中的信息。而信息抽取和向量建模不仅提取了问题特征,而且利用主题词在知识库中确定了候选答案的范围,并将候选答案在知识库中的信息也一并作为特征。传统语义解析方法对知识库信息利用不够,仅仅只关注问题这一方面。此外,语义解析中的词汇映射也较为困难,仅仅通过简单的统计方式,不能有效的将自然语言中的谓语关系映射到知识库中的实体关系。由此可见,如何有效利用知识库信息和利用深度学习通过分布式表达代替基于统计的词汇映射,是两个主要的改进方向。
查询图
仍以一个具体问题为例:
Who first voiced Meg on Family Guy?
为更好的利用知识库信息,利用查询图代替语法解析树对应的逻辑形式,如下图所示: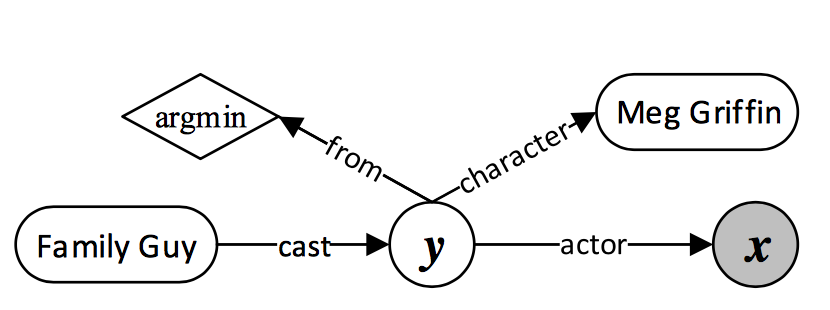
查询图包含四个部分:知识库实体(圆角矩形)、中间变量(白底圆圈)、聚合函数(菱形)和lambda变量,即答案(灰色圆圈)。根据查询图可以转化为对应的lambda表达式,通过lambda表达式在知识库中查询得到答案。
查询图阶段生成
查询图中问题的主题词到答案的这条路径(上图中Family Guy->y->x),包含了所有中间变量,可以作为问题到答案的核心推导过程,称作核心推导链。对于核心推导链里的中间变量,可以对其增加一些约束(与其他实体的关系,如y->character(Meg Griifin))和聚合函数(如y->from(argmin))。
查询图的生成可以分为以下步骤:确定问题主题词、确定核心推导链、增加约束和聚合,这个过程可以用下面的有限状态自动机表示: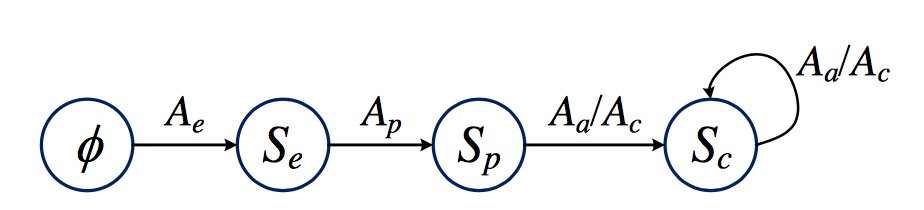
状态集合S={$\phi$,$S_e$,$S_p$,$S_c$}分别表示空集、仅含主题词节点、含核心推导链和含约束节点。动作集合A={$A_e$,$A_p$,$A_a$,$A_c$}分别表示选择主题词节点、选择核心推导链、加入聚合函数和加入约束。查询图的生成实际是一个搜索过程,但如何不加以限制,将达到指数级的复杂度,因此当处于某个状态s时,可以用奖励函数对其进行评估,奖励函数得分越高表示这个状态对应的查询图与正确的语义解析表达越接近。奖励函数可以用一个对数线性(log-linear)模型进行学习,在搜索时利用best-first策略结合优先队列进行启发式搜索。每次从队列中取出得分最高的状态分别执行动作集中的各个动作,生成新的状态并入队,始终记录得分最高的状态,最终得分最高的状态便是最后的查询图。下面仍以“Who first voiced Meg on Family Guy?”这个问题为例,简述各个阶段。
主题词链接
查询图生成的第一个动作是确定问题中的主题词,作者称为主题词链接。文中使用S-MART作为实体链接系统,该系统针对带噪音的短文本设计,用于提取问句中的主题词,并为相应的“实体-自然语言短语”链接给出一个打分,作者保留得分最高的10个实体作为候选,如下图所示: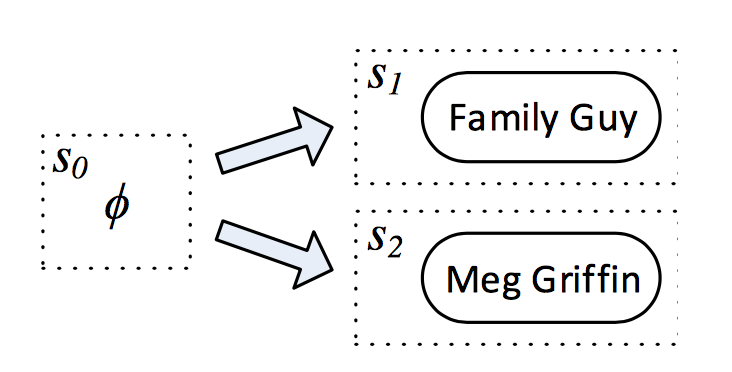
核心推导链
确定主题词后,在知识库中查找对应的实体节点,将该实体节点周围长度为1的路径和长度为2并且包含CVT节点(Compound Value Types,freebase中用于表示复杂数据而引入的概念)的路径(如下图$s_3$,$s_4$)作为核心推导链候选: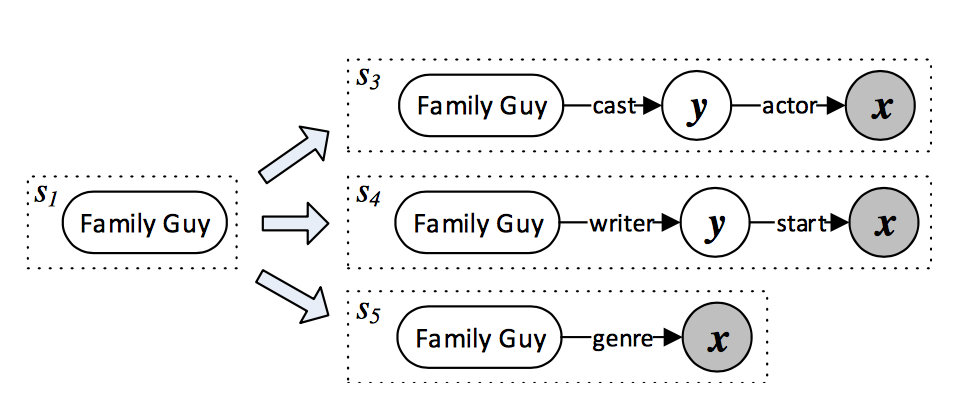
核心推导链其实是将自然语言问题映射为一个谓语序列(如cast-actor),可以利用CNN对该映射进行打分。将自然语言和谓语序列作为输入分别经过两个不同的CNN,得到对应的300维向量表示,利用相似度(如余弦距离)计算自然语言和谓语序列的语义相似度得分。值得注意的是,CNN的输入是字母三元组,作者把每个单词拆分为若干个字母三元组。
增加约束和聚合函数
通过增加约束和聚合函数对查询图进行扩展,同时缩小答案的范围。作者基于自定义的规则来增加约束和聚合函数,例如当实体链接检测到句子中其他实体,则增加一个约束;如果句子中出现了first等时序敏感词,则增加聚合节点。大致过程如下图所示: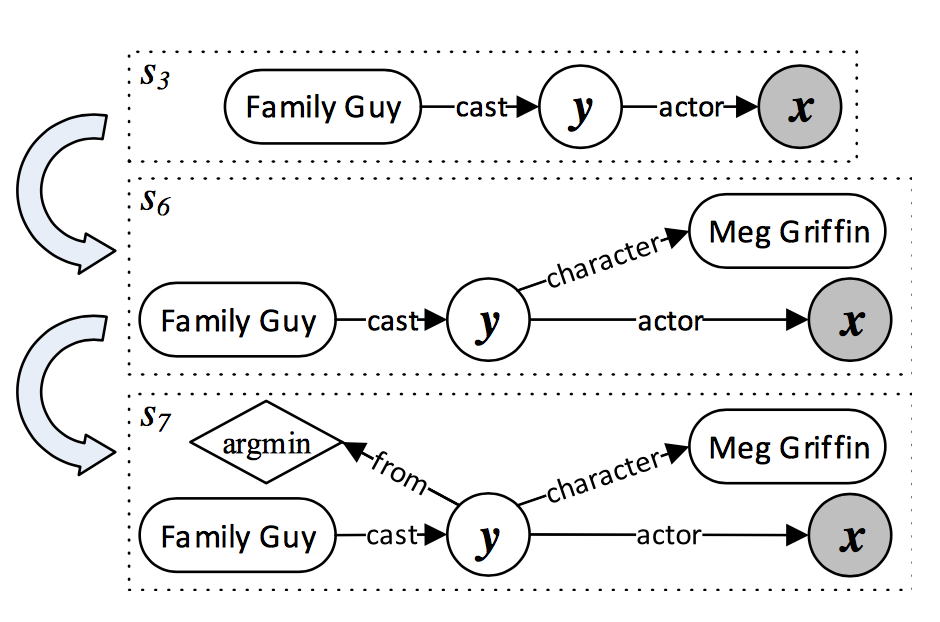
奖励函数
上文已提到,奖励函数利用对数线性模型,仍然需要手工定义特征,用于模型训练。特征主要从三个方面选取:主题词链接、核心推导链和增加约束聚合。由于手工定义的特征种类较多,规则比较复杂,具体可参考论文[4]。问句“Who first voiced Meg on Family Guy?” 对应的查询图和各方面特征得分如下图所示: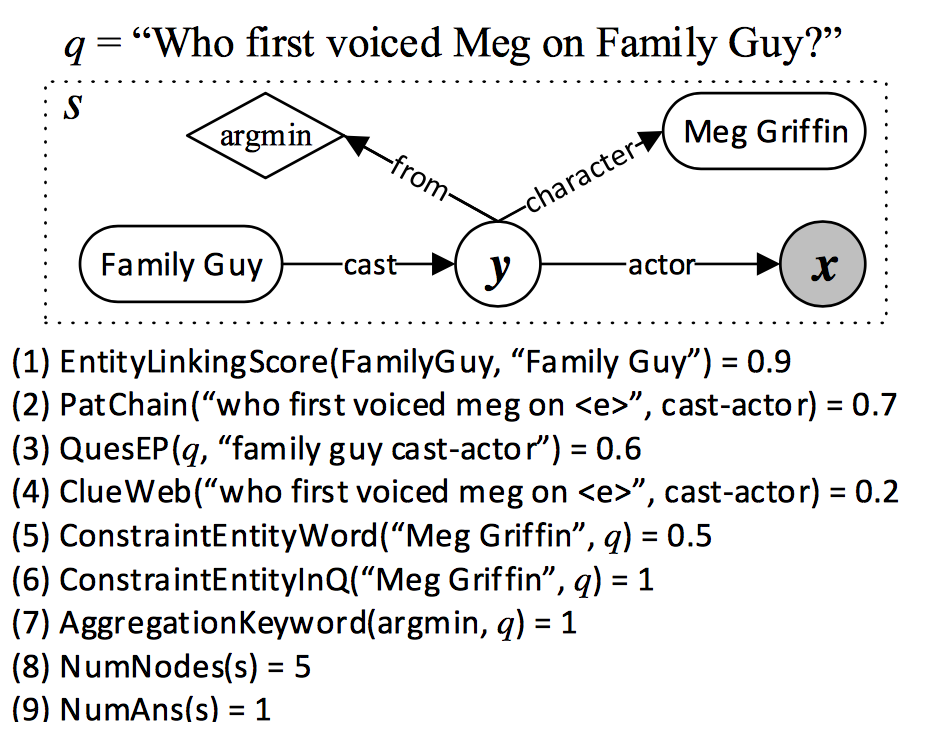
模型训练
在信息抽取方法中,模型是根据特征判断答案是否正确进行训练的,是一个二分类过程。本文中根据查询图得到的实体和真实答案的F1-score进行排序,利用lambda-rank算法对一个单层神经网络进行训练。lamdba-rank算法是对RankNet算法的改进,用于排序优化算法。这种方法相对于二分类的精确匹配对答案的要求相对“宽松”,虽然有时查询图得到的答案与正确答案不完全相同,但至少比错误的查询图要好。
实验结果
截止2016年,本文在WebQuestion数据集取得了最好的效果,达到了52.5的F1-score。
模型对比
2014年以前主要都是基于语义解析、信息抽取等传统方法。自2015年开始,出现了基于深度学习技术的端到端系统,相比传统方法整体有了一些提升。但截至2016年,最好的方法是利用深度学习技术对传统的语义解析过程进行提升实现的。综合来看,单纯端到端的系统确实减少了大量人工构建特征所耗费的工作量,但传统方法仍然有许多可以借鉴的点,而且由于KBQA的答案信息主要来自知识库,而知识库中的信息相对结构化,这些结构化信息对于寻找答案有着很强的指导,因此不论是传统方法也好,还是基于深度学习的端到端系统,如何充分利用知识库中的信息,并且和问题建立有效联系,都是KBQA中最重要的一点。下图为各模型在WebQuestion数据集上的测试结果: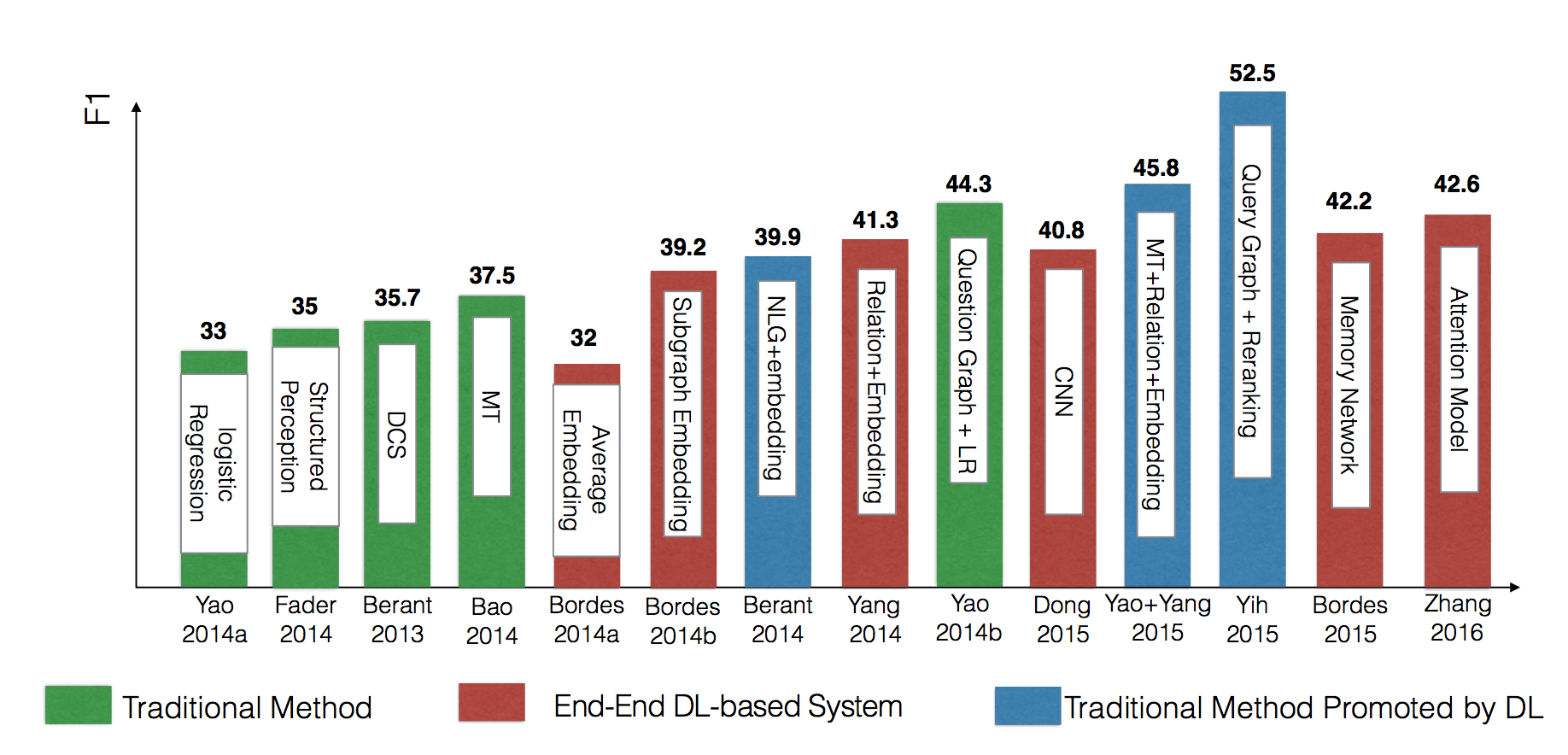
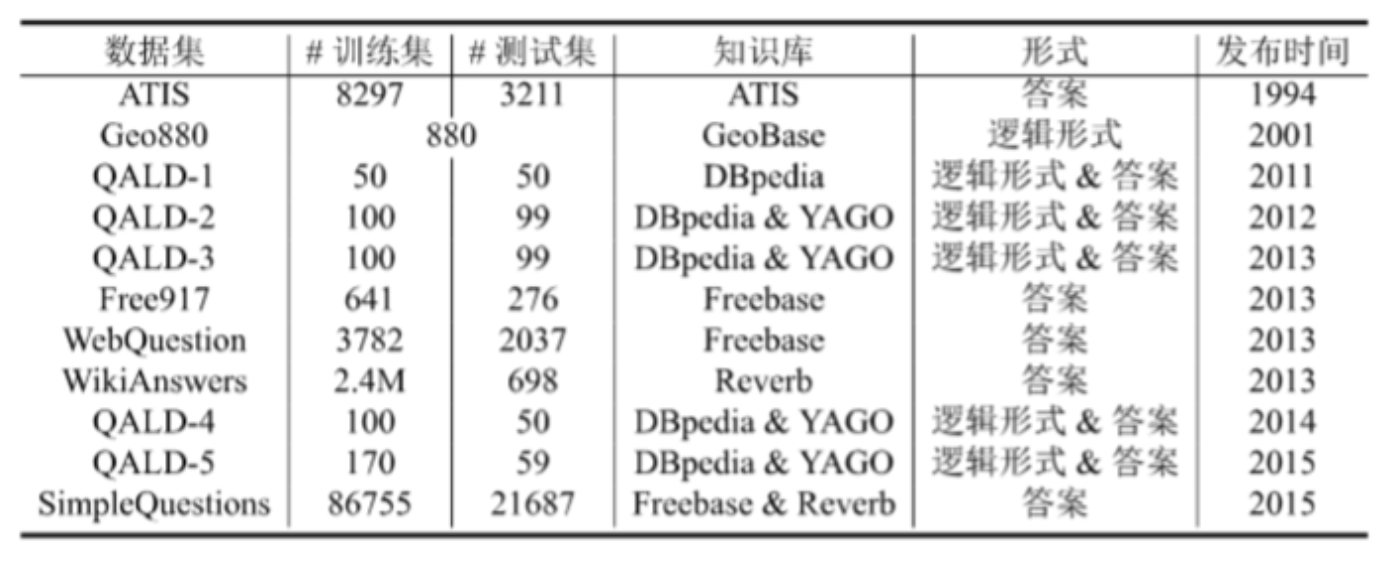
公开数据集
参考资料:
揭开知识库问答KB-QA的面纱知乎专栏
刘康-基于深度学习的知识库问答研究进展
引用
[1] Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[J]. Proceedings of Emnlp, 2014.
[2] Yao X, Durme B V. Information Extraction over Structured Data: Question Answering with Freebase[C]// Meeting of the Association for Computational Linguistics. 2014:956-966.
[3] Bordes A, Chopra S, Weston J. Question Answering with Subgraph Embeddings[J]. Computer Science, 2014.
[4] Yih W T, Chang M W, He X, et al. Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base[C]// Meeting of the Association for Computational Linguistics and the, International Joint Conference on Natural Language Processing. 2015:1321-1331.