Seq2Seq模型在自然语言处理领域应用广泛,例如机器翻译、句子生成和单轮对话。从更为广泛的角度看,其属于Encoder-Decoder网络,但Seq2Seq模型对于实体名字、谚语和成语在decoder时往往表现欠佳,例如:
原文:第76届金球奖,布莱德利·库珀、LadyGaga主演的《一个明星的诞生》歌曲《Shallow》获得最佳原创歌曲。
翻译:在第76届金球奖上,布莱德利·库珀和LadyGaga主演的歌曲《浅滩》获得了最佳原创歌曲奖。(zh-en-zh)
在对于歌曲名字的翻译上出现了错误,而在人工翻译中一般会将这些词语“照抄”,也就是本文主要说明的copy机制。
RNN Encoder-Decoder
传统的RNN Encoder-Decoder模型编码过程为: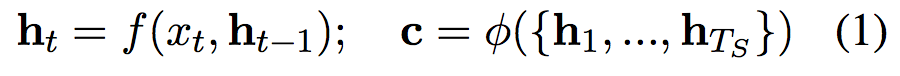
解码过程为: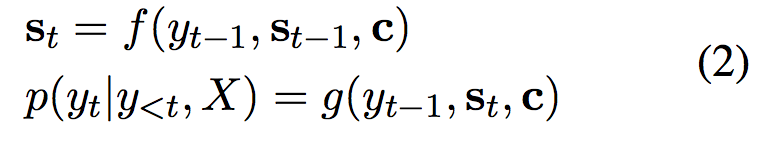
CopyNet
模型整体结构图: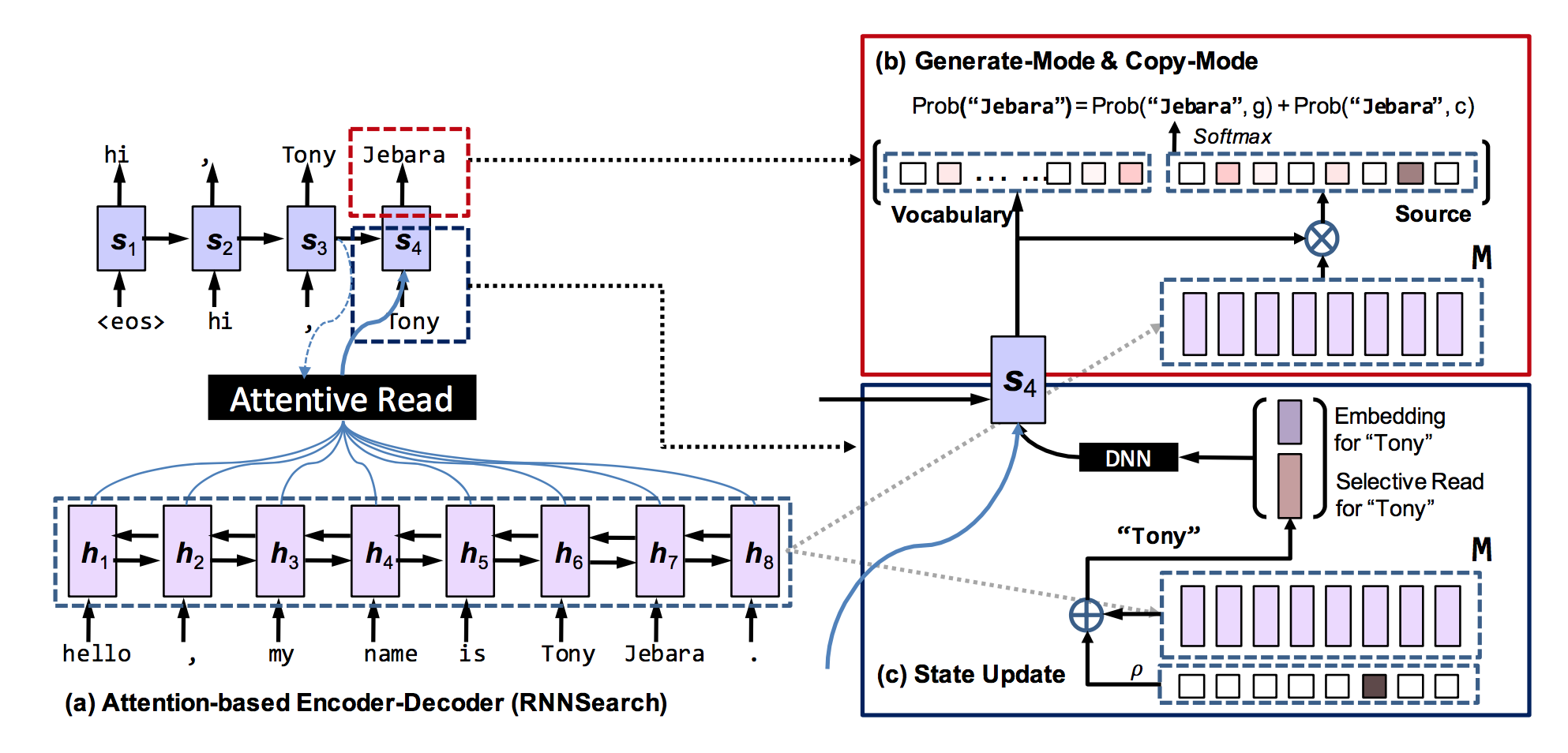
CopyNet与传统RNN模型在Decoder阶段主要有三点区别:
- 预测。copynet根据generate-mode和copy-mode混合模型预测words。
- 状态更新。copynet在更新t时刻的状态时,不仅使用t-1时刻预测word的embedding,还使用其附近的location-specific隐层状态。
- Reading M(M定义见模型结构图)。除了在M中使用attentive read机制外,copynet还使用了“selective read”机制,使模型具有content-based addressing和location-based addressing的混合能力。
Prediction with Copying and Generation
给定decoder RNN在t时刻的状态,目标word预测概率由以下混合概率公式决定: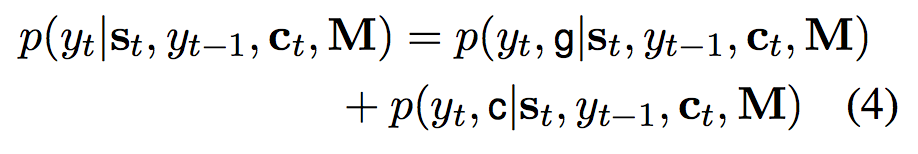
g表示generate-mode, c表示copy mode。
具体计算方法为: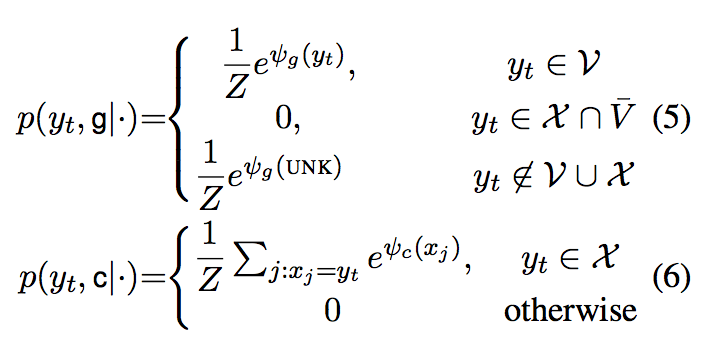
Z表示两个mode共享的规范系数: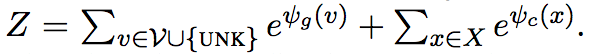
Generate-Mode Score
与一般的RNN encoder-decoder 类似: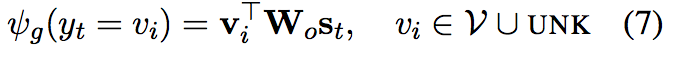
Copy-Mode Score
第j个word得分计算公式为: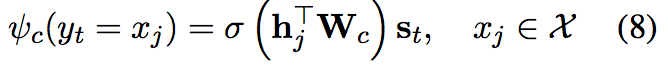
State Update
Copynet利用解码器前一个状态$s_{t-1}$和公式2中的context vector $c_t$来更新当前解码器状态$s_t$。针对copying机制,$y_{t-1}$->$s_t$做了一些修改。$y_t$表示为$\left[ e\left( y_{t-1}\right) ;ζ\left( y_{t-1}\right) \right] ^{T}$。其中$e(y_t-1)$表示$y_{t-1}$对应的词向量。$ζ\left( y_{t-1}\right)$表示M中隐层状态的加权和,计算公式为: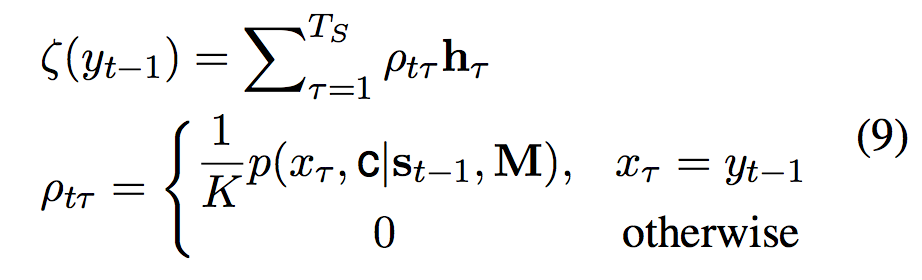
公式中各个参数具体说明见论文。直观来看这个公式,当$x_\tau=y_{t-1}$时,例如整体模型结构图中输入序列的“Tony”与解码器输出的“Tony”相同时,copy机制会影响$y_{t-1}$,进而影响$s_t$状态的更新。
这一块没有理解很透彻,从encoder-decoder角度看,模型这样设计的合理性是什么?猜测是因为“拷贝的惯性”,当前词需要从编码器输入copy时,那么下一个词也很有可能需要拷贝?当然,论文中将解码器概率作为一个四分类问题,通过数据集训练来决定一个输入词的分类概率,这样看倒是能理解一些。解码器分类示意图: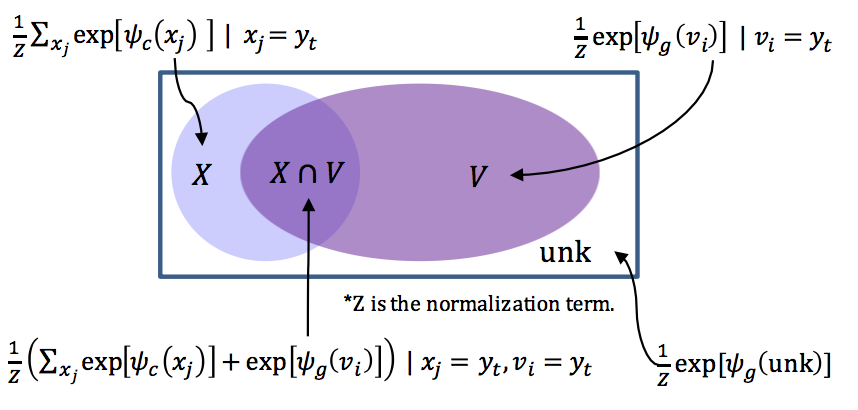
实验
作者在Text Summarization和Single-turn Dialogue两个任务上进行了试验,取得了较好的效果。文本总结示例:
在实际使用copynet模型时遇到了一些问题,通过对相似句子对的训练,期望可以改善Seq2Seq模型在翻译中对实体、成语等处理不佳的情况,实验结果表明在解码时确实能有效处理这些需要copy的词语,但是会出现多次重复的情况,例如:
正确句子:嫦娥四号着陆器接受光照自主唤醒。
生成句子:嫦娥四号嫦娥四号嫦娥四号着陆器接受光照自主唤醒。
猜测可能是由于在$s_{t-1}$->$s_t$更新时,通过selective reader引入了$h_\tau$,而相邻单词$h_{\tau+1}$与$h_\tau$数值也比较接近,导致$s_t$与$s_{t-1}$也比较接近,使解码器输出的单词相同。具体原因有待进一步探究。