简介
互联网搜索诞生初期,检索模型使用的特征相对简单,这些特征主要基于query与doc之间的相关度来对文档进行排序。另一种传统排序模型是重要性排序模型,此时模型不考虑query ,而仅仅根据文档(网页)之间的图结构来判断doc的重要程度,例如PageRank排序模型。而随着互联网不断发展,海量数据的产生,更多复杂有效的特征被用于搜索排序,人工调参已不能满足需求,此时机器学习开始在搜索排序领域得到应用,learning to rank逐渐成为热门研究方向。
搜索
搜索的目标是选择与用户输入query最相关的一组文档,目前主要步骤如下:
- 粗排:query-doc匹配,得到一组与query相关的文档,目前一般采用倒排索引实现;
- 精排:选取更多特征,按照用户点击该doc的可能性大小排序,Learning to rank即是实现该部分的机器学习模型。
机器学习排序系统
典型的机器学习排序系统如下图所示:![]()
Learning to rank
包含pointwise方法、pairwise方法和listwise方法三种类型。
(1) pointwise方法:对于某一个query, 判断每个doc这个query的相关度,由此将docs排序问题转化为了分类(比如相关、不相关)或回归问题(相关程度越大,回归函数的值越大)。其L2R框架具有以下特征:
- 输入空间中样本是单个 doc(和对应 query)构成的特征向量;
- 输出空间中样本是单个 doc(和对应 query)的相关度;
- 假设样本满足打分函数;
- 损失函数评估单个 doc 的预测得分和真实得分之间差异。
(2) pairwise方法:该方法并不关心某一个doc与query相关程度的具体数值,而是将排序问题转化为任意两个不同的docs di和dj谁与当前的query更相关的相对顺序的排序问题。一般分为di比dj更相关、更不相关和相关程度相等三个类别,分别记为{+1, -1, 0},由此便又转化为了分类问题。其 L2R 框架具有以下特征:
- 输入空间中样本是(同一 query 对应的)两个 doc(和对应 query)构成的两个特征向量;
- 输出空间中样本是 pairwise preference;
- 假设空间中样本满足二变量函数;
- 损失函数评估 doc pair 的预测 preference 和真实 preference 之间差异。
(3) listwise方法:将一个query对应的所有相关文档看做一个整体,作为单个训练样本。其 L2R 框架具有以下特征:
- 输入空间中样本是(同一 query 对应的)所有 doc构成的多个特征向量(列表);
- 输出空间中样本是这些 doc与对应 query的相关度排序列表;
- 假设空间中样本满足多变量函数,对于 docs 得到其排列,实践中,通常是一个打分函数,根据打分函数对所有 docs 的打分进行排序得到 docs 相关度的排列;
- 损失函数分成两类,一类是直接和评价指标相关的,还有一类不是直接相关的。
由于评价指标通常是离散不可微的,直接优化ranking评价指标并不简单,通常有以下处理方式:
- 优化基于评价指标的 ranking error 的连续可微的近似,这种方法就可以直接应用已有的优化方法,如SoftRank,ApproximateRank,SmoothRank。
- 优化基于评价指标的 ranking error 的连续可微的上界,如 SVM-MAP,SVM-NDCG,PermuRank。
- 使用可以优化非平滑目标函数的优化技术,如 AdaRank,RankGP。非直接相关的损失函数则不再使用与评价相关的loss来优化模型,而是设计能衡量模型输出与真实排列之间差异的 loss,如此获得的模型在评价指标上也能获得不错的性能。例如 :ListNet,ListMLE,StructRank和BoltzRank。
主要模型分类
按照这三种类型,可以将主要模型做如下梳理: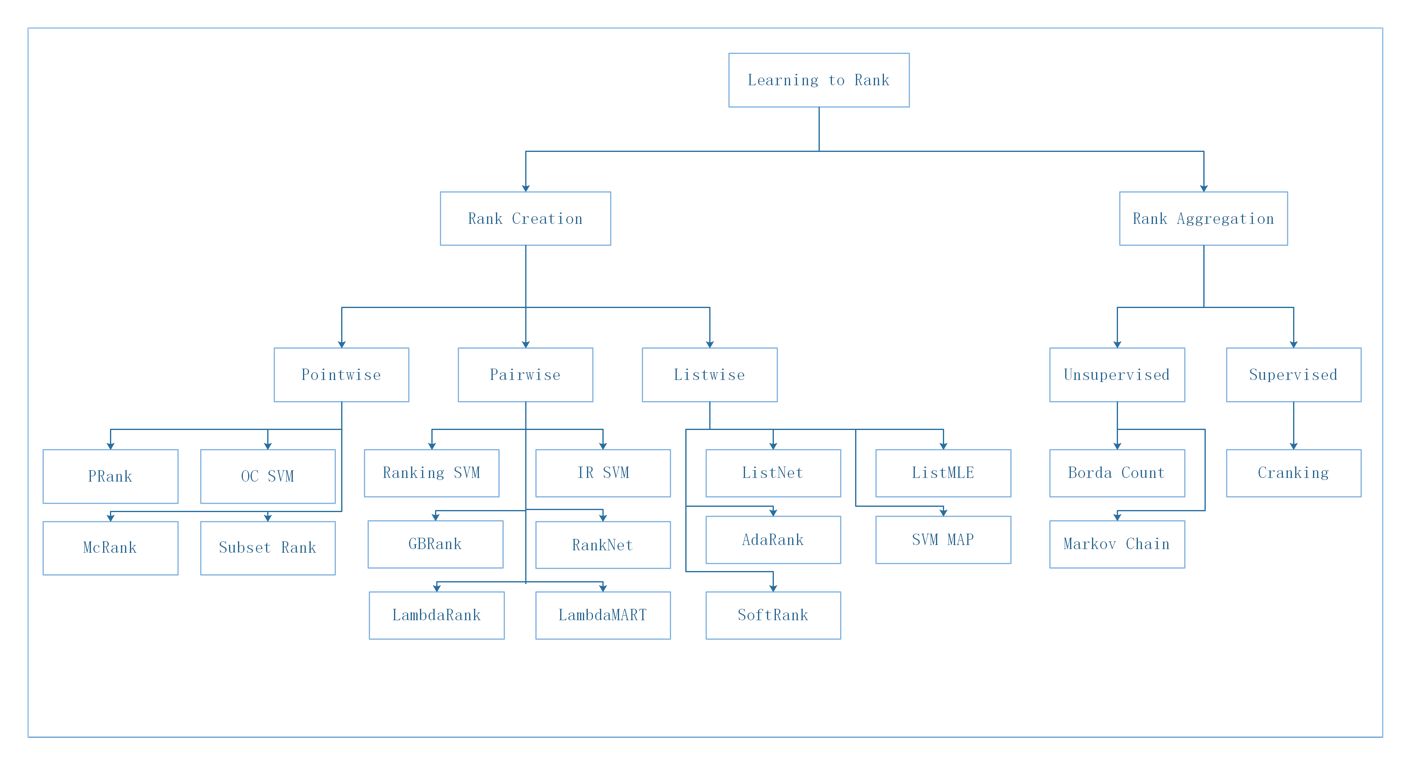
图中Rank Creation指给定查询Query和文档Docs,得到Docs排序结果;Rank Aggregation指综合多个不同的Ranking System的排序结果,得出最终排序结果。
XGBoost
下面以xgboost模型为例,说明如何完成排序。大致过程如下:
训练
- 获取训练数据;
- 构造特征候选集,完成训练样本准备;
- 基于xgboost寻找划分点,重复该步至不能再分裂划分点;
- 通过最小化pairwise loss生成下一棵树;
- 生成设定数量的树后,训练完成;
测试
- 输入测试样本;
- 根据训练所得模型和打分函数进行打分;
- 获得每个
值得注意的是,目前使用比较多的XGBoost ranking模型是LambdaRank,但尚未完成,参考dmlc/xgboost .
代码示例
参考资料
用xgboost做排序任务——xgboost下的learning2rank
Learning to Rank系列之概述
Learning to Rank 概述