背景知识
文本搜索中,词权重的信息可用于关键词提取、关键段落识别和相关分数计算等,常用的方法是TF-IDF,TF表示词频,IDF表示逆文档频率,两者相乘得到词权重。TF-IDF的思想基于以下假设:
- 某个词语出现次数越多,其权重越高,对应TF值;
- 在所有文档集合中,包含该词的文档越少,其权重越高,例如”的“、”是“等词语几乎在大部分文档中都会出现,对应的权重较低,而”的确“、”是非“等词则只在部分文档中出现,其权重较高。对应IDF值。
除了TF-IDF算法,还可以参考PageRank算法进行改进,设计关键词提取TextRank算法,具体内容参考TextRank算法。
TF-IDF和TextRank算法计算词权重存在以下几个问题:
- 没有词语上下文语义信息,在各个文档中都是进行硬匹配,统计次数;
- 词频不一定与权重呈正相关,出现越多的词语不一定权重就越高。例如论文中举的例子:
 当query=”stomach”时,虽然两篇文档出现了相同次数的”stomach”,但是第一篇中”stomach”是主题内容,而第二篇中只是多个并列主题中的一个,显然第一篇中”stomach”的权重应该更高;
当query=”stomach”时,虽然两篇文档出现了相同次数的”stomach”,但是第一篇中”stomach”是主题内容,而第二篇中只是多个并列主题中的一个,显然第一篇中”stomach”的权重应该更高; - TextRank算法中的词共现不一定与权重正相关。参考PageRank的思想,TextRank计算词权重时有:如果一个词与多个词共现,那么说明这个词的权重较高;如果一个权重较高的词与某个词共现,那么该词的权重也会相应提高。例如”的“、”是“等词可能与许多词语共现,但其权重显然不能太高。
总结一下,传统的方法主要存在以下问题:
- 没有利用词的上下文信息;
- 权重的衡量方法不合理。
DeepCT
针对以上两个问题,论文提出了DeepCT框架,主要包含两部分:
- 利用预训练语言模型BERT获得词的向下文表示;
- 通过有监督的学习来计算词权重。
词向量到权重通过一个线性变换进行映射:
$$\begin{gather*} \hat{y}_{t, c}=\vec{w} T_{t, c}+b \end{gather*}$$其中$T_{t, c}$表示词语$t$在文本$c$中的向量表示,$\vec{w}, b$表示权重和偏置。
训练目标是对于每个词语,最小化其真实标签和预测标签的均方误差:
$$\begin{gather*} \operatorname{loss}_{M S E}=\sum_{c} \sum_{t}\left(y_{t, c}-\hat{y}_{t, c}\right)^{2} \end{gather*}$$其中$c$表示文档,$t$表示文档中的词语,$y$表示真实标签,$\hat{y}$表示预测标签。
预测时,词权重的范围为$(-\infty, \infty)$,但由于真实标签大多在[0,1],因此大部分预测权重也在[0,1]。
doc词权重
词权重如何衡量?上文中提到论文是利用有监督的方法进行学习的,那么有监督的数据来自哪里,即真实的词权重标签如何构建?文中提出了query term recall作为衡量词权重的方法,个人认为这也是该论文最大的亮点,具体地:
$$\begin{gather*} Q T R(t, d)=\frac{\left|Q_{d, t}\right|}{\left|Q_{d}\right|} \end{gather*}$$其中$Q_{d}$表示与文档d相关的query集合,$t$是$Q_{d}$的子集,表示包含词语$t$的query集合,$Q T R(t, d)$表示文档d中词语t的query term recall weight,$Q T R \in [0,1]$。query term recall weight的思想是:对于文章中的各个词,用户输入的查询词语能够反映文档的主要内容。实际中我们可以基于点击、阅读和转发等日志来构建query和doc的相关数据,进一步体现这一思想。例如对于一篇介绍芒果的文章,其对应产生点击的query可能大部分都包含了”芒果“这个词,而少部分query中可能也包含了其他水果,例如”芒果和苹果维生素C含量高吗?“,但对于整个query集合,一般来说包含”芒果“的query是最多的,通过上面QTR的计算方法我们就可以将文章中的”芒果“一词设置较高的权重。
论文中新定义了一个$\mathrm{TF}_{\text {DeepCT }}$来替换倒排索引中的原始TF值,计算公式为:
$$\begin{gather*} \mathrm{TF}_{\text {DeepCT }}(t, d)=\operatorname{round}\left(\hat{y}_{t, d} * N\right) \end{gather*}$$其中$\hat{y}_{t, d}$表示预测权重值,$N$表示要缩放到的整数,例如N=100。对于计算得到的权重可根据实际需要进行相应处理。
query词权重
与doc词权重的计算方法类似,利用term recall weight来衡量query中的词权重:
$$\begin{gather*} T R_{t, q}=\frac{\left|Q_{q, t}\right|}{\left|Q_{q}\right|} \end{gather*}$$其中$D_{q}$表示与query相关的doc集合,$D_{q, t}$是$D_{q}$的子集,表示包含词语$t$的doc集合,$T R(t, q)$表示词语t在查询q中的term recall weight ,$T R \in [0,1]$。
个人感觉doc词权重的计算方法更有实际应用价值,因为doc是相对静态的,可以离线计算好,而query是动态的,如果使用较为复杂的BERT模型获取其上下文表示,可能带来性能问题。此外,对于搜索引擎而言,文档内容相对静态,而用户输入是动态的,千变万化。因此按照上述构建QTR和TR的方法,用户输入的多样性能保证doc词权重的区分度,而对于某个query,文档集合中的文章多样性并不一定能保证对应到query词权重的区分度。例如对于query=”深圳人口是阳江的多少倍?“,一般来说包含”深圳“的文章可能比”阳江“多很多,对应我们构建的TR值深圳也会远远大于阳江,但在query中两者是并列关系,权重基本相同。
实验结果
论文中使用预训练的BERT获取上下文表示,在MS MARCO和TREC-CAR数据集上进行了测试,具体模型和参数可以参考原论文,实验结果如下图所示:
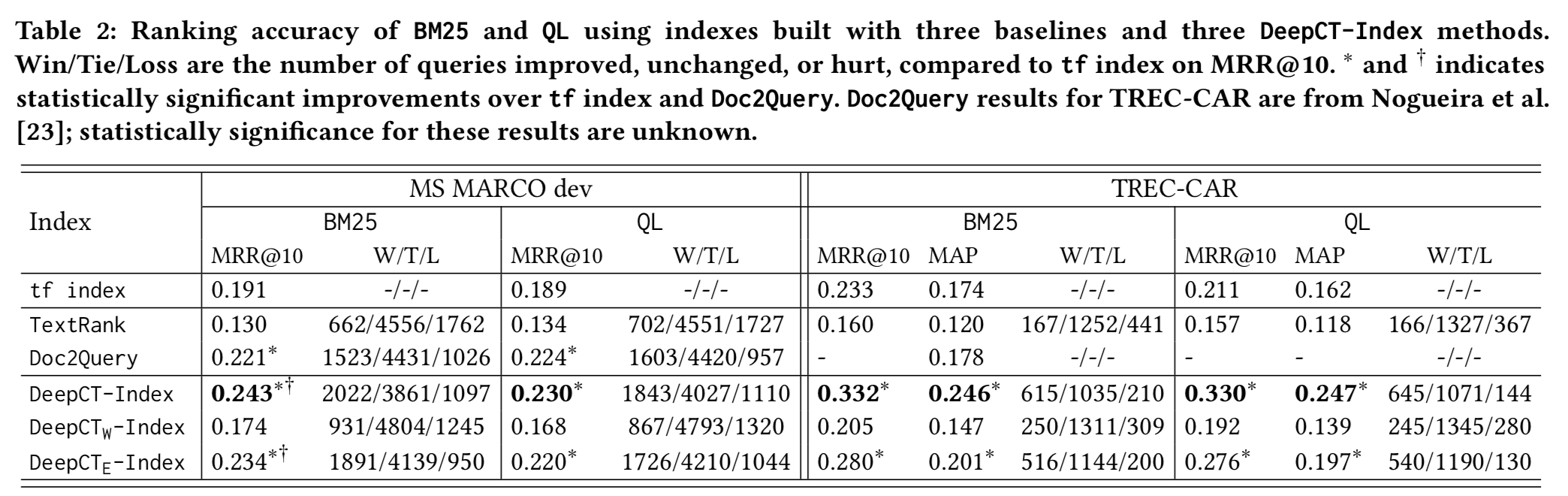
实验表明根据DeepCT权重构建索引的方法优于BM25和TextRank等方法。