下图为整理的NLP算法工程师知识体系,数字1,2,3表示学习技能的优先级,绿色饼状图表示掌握该技能的程度。
技能掌握包含三个方面:
- 理论知识。需要全面总结并包含自己的理解,以博客文章形式输出;
- 工程实践。需要动手实验并记录总结,以博客文章形式输出;
- 代码编写。需要整理源码或自己编码, 并push到Github上。
同时要关注算法行业的最新发展趋势,与时俱进,不断扩展技能包。
下图为整理的NLP算法工程师知识体系,数字1,2,3表示学习技能的优先级,绿色饼状图表示掌握该技能的程度。
技能掌握包含三个方面:
同时要关注算法行业的最新发展趋势,与时俱进,不断扩展技能包。
NLP领域最基础但也最重要的问题是如何表示词语、句子和篇章,word2vec的出现是一个很大的进步,可以将词语编码为包含语义信息的向量,通过向量之间的距离可以在一定程度上衡量词语的相似度。得益于深度学习技术的发展,在获得词语向量表示后,可以利用CNN、LSTM和Transformer等模型对句子和篇章进行表示。但是深度学习模型需要大量数据来学习文本的表示,训练数据的质量和数量常常制约了模型的效果,以BERT为开端,大规模预训练语言模型开始得到广泛应用。
文本搜索中,词权重的信息可用于关键词提取、关键段落识别和相关分数计算等,常用的方法是TF-IDF,TF表示词频,IDF表示逆文档频率,两者相乘得到词权重。TF-IDF的思想基于以下假设:
除了TF-IDF算法,还可以参考PageRank算法进行改进,设计关键词提取TextRank算法,具体内容参考TextRank算法。
TF-IDF和TextRank算法计算词权重存在以下几个问题:
 当query=”stomach”时,虽然两篇文档出现了相同次数的”stomach”,但是第一篇中”stomach”是主题内容,而第二篇中只是多个并列主题中的一个,显然第一篇中”stomach”的权重应该更高;
当query=”stomach”时,虽然两篇文档出现了相同次数的”stomach”,但是第一篇中”stomach”是主题内容,而第二篇中只是多个并列主题中的一个,显然第一篇中”stomach”的权重应该更高;总结一下,传统的方法主要存在以下问题:
文本搜索领域常见的召回算法大致可以分为基于词汇匹配和向量召回两种,基于词汇匹配的算法以BM25为代表,通过计算query和doc词语匹配度来衡量相关性;向量化召回算法则经历了从无监督计算预训练词向量(word2vec、Glove)相似度,到有监督地计算query和doc相似度(DSSM),再到基于大规模预训练语言模型(BERT)计算相似度的迭代过程。
代表算法为BM25,可以理解为tf-idf算法的改进,参考链接:
https://cloud.tencent.com/developer/article/1056867?from=article.detail.1331631
Lexical IR算法得益于高效的倒排索引技术,十分高效,仍是目前主要的检索方法。其主要面临以下两个问题:
上述两个问题可以通过词形归一、N-grams匹配和查询扩展等技术进行缓解,但本质上仍然是基于词袋假设,无法从根本上解决。
业界广泛流传着这样的一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。特征体系的设计、优化是取得理想结果的基础,那么对于文本搜索,应该如何设计特征呢?本文讨论常见的文本搜索场景,输入为query,目标是将相关性较高的文章排在前面。关于模型,可参考搜索排序算法。
特征可以大致分为以下几类:
搜索和推荐系统一般包含召回和排序两个阶段,搜索排序主要关注相关性,常见的模型可以参考搜索排序算法。推荐模型则关注用户偏好,一般用CTR点击率来描述,常用的推荐模型有:
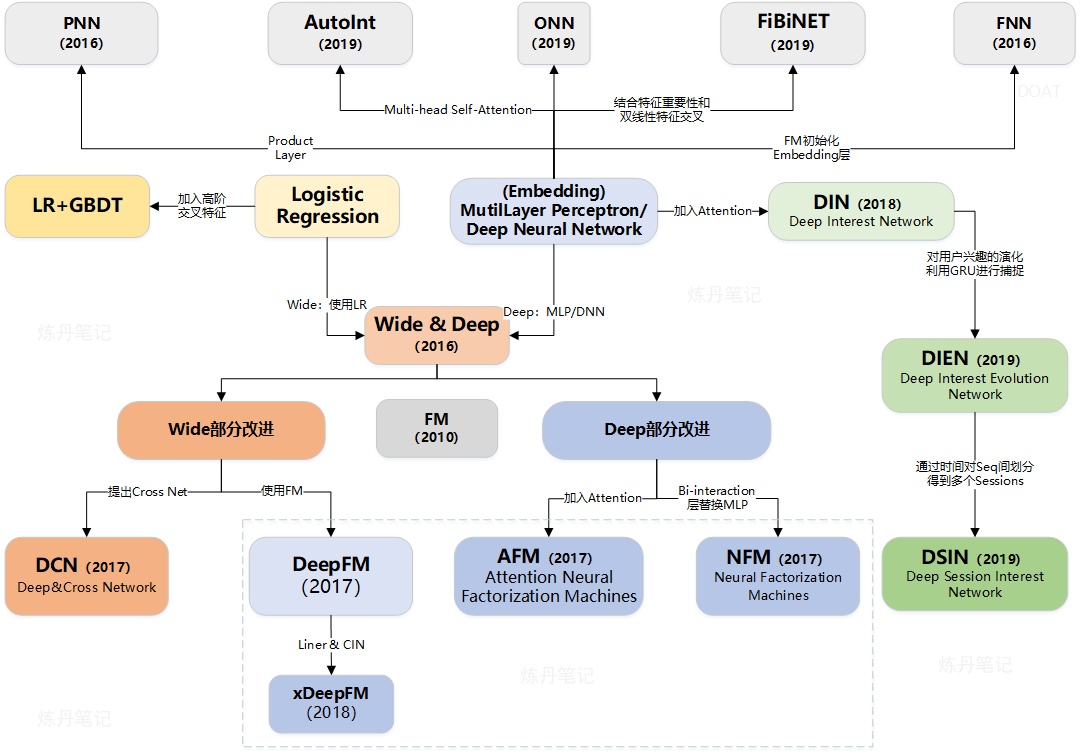
本文重点关注应用较为广泛的LR、GBDT、FM、Wide&Deep和DIN模型,其中LR、GBDT和FM部分大部分图片引用自刘启林的机器学习笔记。
本篇论文获得SIGIR 2020 Best Paper,旨在通过构建公平的无偏统计量,解决动态排序中的不公平问题。排序算法广泛应用于推荐和搜索场景,但目前的算法大多存在马太效应,例如热搜场景,排名越靠前被点击的概率也就越大,在一段时间内,越是靠前的文章就越会被人点击,然后其排名持续提升,而初始排在后面的文章由于没有得到公平曝光而逐渐无人问津。不过仅仅考虑热搜场景的话,这里的马太效应是符合要求的,但在其他排序场景中,就会存在一些问题,例如在购物场景下,初始排名靠后的商品由于无法得到充分曝光相对成交量很少,这对商家来说是难以接受的。
以新闻网站动态排序文章为例,假设有六篇文章,且没有关于排名的信息,那么我们可能向第一个用户提供随机的排名。根据该用户的点击行为更新排名,类似的,根据后续的用户点击行为,持续更新排名。最后找到一个适合大多数用户的排名,如下图所示: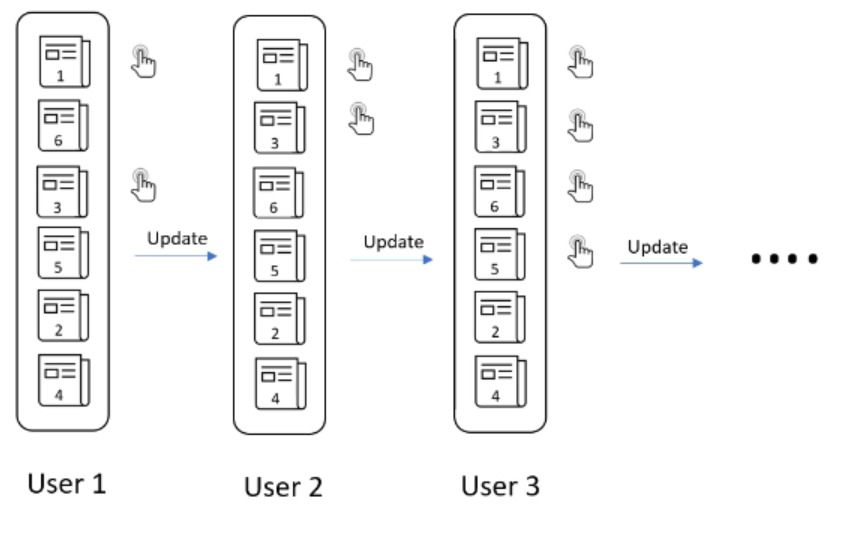
这种动态学习排序的方式存在两个问题:
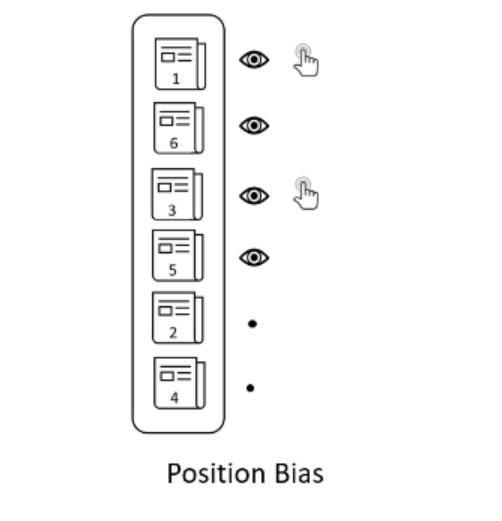
这是一个“富者越富”的问题,上图中的文章4上升到顶部的机会显然低于从一开始就在顶部的文章。
曝光分配不均。假设我们能够以某种方式计算出文章的真实相关性,仍然会存在问题。假设上文中提到的六篇文章属于$G_{Left}$和$G_{Right}$两组,即有两组用户分别喜欢对应的文章,如下图所示:
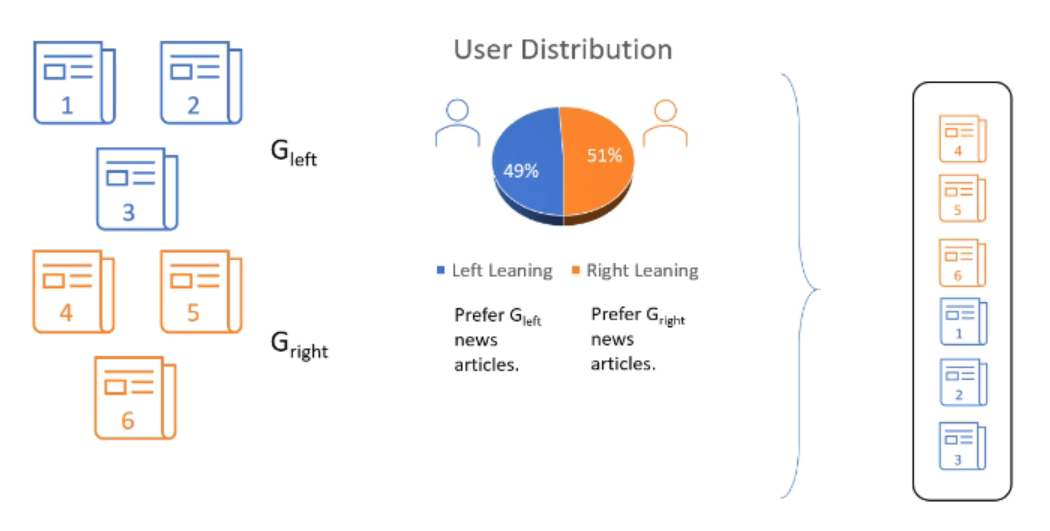
根据排序规则,由于喜欢Right组文章的用户更多,因此会把Right组的文章全部排在前面,这导致Left组文章无法得到公平曝光,而相应的Left组用户也开始不喜欢这个产品,导致用户流失。但喜欢两个组文章的用户数只有2%的差异,这显然是不合理的。
那么公平的动态排序算法要具有两个性质:

这篇文章希望站着把三件事办了:
关于Lambda梯度要从RankNet说起,RankNet提出了一种概率损失函数来学习Ranking Function,并应用Ranking Function对文档进行排序。LambdaRank在RankNet的基础上引入评价指标Z (如NDCG、ERR等),其损失函数的梯度代表了文档下一次迭代优化的方向和强度,由于引入了IR评价指标,Lambda梯度更关注位置靠前的优质文档的排序位置的提升,有效的避免了下调位置靠前优质文档的位置这种情况的发生。LambdaRank相比RankNet的优势在于分解因式后训练速度变快,同时考虑了评价指标,直接对问题求解,效果更明显。 详细内容可以参考搜索排序算法。
MART(Multiple Additive Regression Tree)的另一个名字叫GBDT(Gradient Boosting Decision Tree),理解GBDT要从BT开始。
典型的搜索排序算法框架如下图所示,分为线下训练和线上排序两个部分。模型包括相关性模型、时效性模型、个性化模型和点击模型等。特征包括Query特征、Doc特征、User特征和Query-Doc匹配特征等。日志包括展现日志、点击日志和Query日志。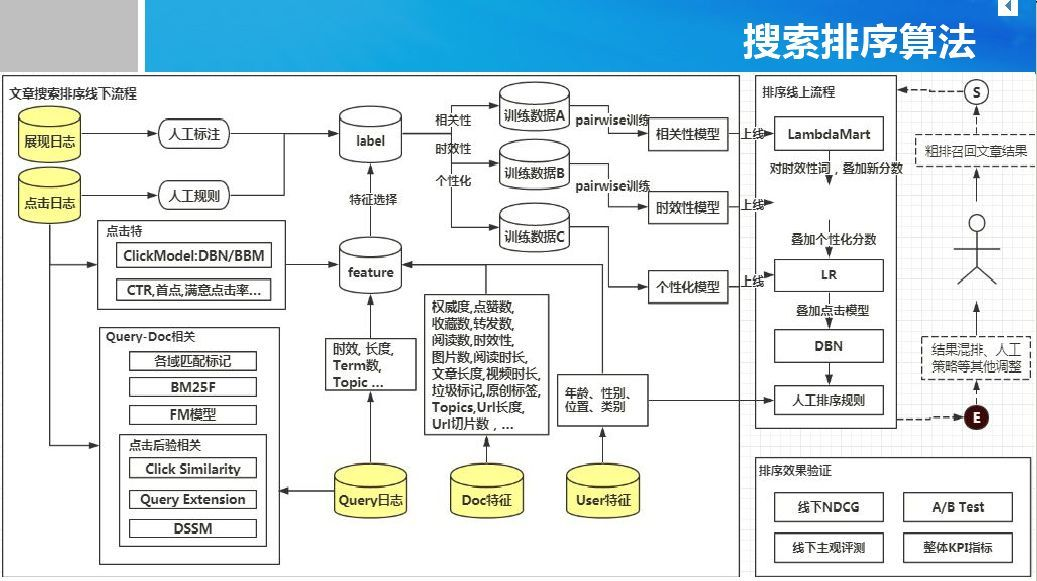
Query特征:意图分类、关键词、词权重等。
Doc特征:文章分类、长度、点赞数等。
User特征:年龄、性别等。
Query-Doc匹配特征:类别匹配、BM25。
点击特征:CTR、首次点击等。
展现日志:理论上可根据经验进行人工标注打分,并且作为模型的启动训练数据。
点击日志:用户的点击行为日志,可以用于Query日志挖掘,进行查询扩展等,例如多个query搜索结果用户都点击了同一篇文档,则可认为这些query相似。
Query日志:用于和点击/转化数据做联合分析。
相关性模型:Learning to Rank模型
时效性模型:[待补充]。
个性化模型:逻辑回归(Logistic Regression)。
点击模型:深度置信网络(Deep Belief Networks)。
互联网搜索诞生初期,检索模型使用的特征相对简单,这些特征主要基于query与doc之间的相关度来对文档进行排序。另一种传统排序模型是重要性排序模型,此时模型不考虑query ,而仅仅根据文档(网页)之间的图结构来判断doc的重要程度,例如PageRank排序模型。而随着互联网不断发展,海量数据的产生,更多复杂有效的特征被用于搜索排序,人工调参已不能满足需求,此时机器学习开始在搜索排序领域得到应用,learning to rank逐渐成为热门研究方向。
搜索的目标是选择与用户输入query最相关的一组文档,目前主要步骤如下:
典型的机器学习排序系统如下图所示:![]()
BERT除预训练代码run_pretraining.py外,还提供了run_classifier.py用于文本分类和run_squad.py用于阅读理解,下面通过对比三个代码总结出如何快速基于BERT做二阶段fine tune的方法。此外,如果TF Hub中有对应任务可使用的预训练模型,也可直接使用,例如同样用于分类的run_classifier_with_tfhub.py。
代码的整体流程如下图所示: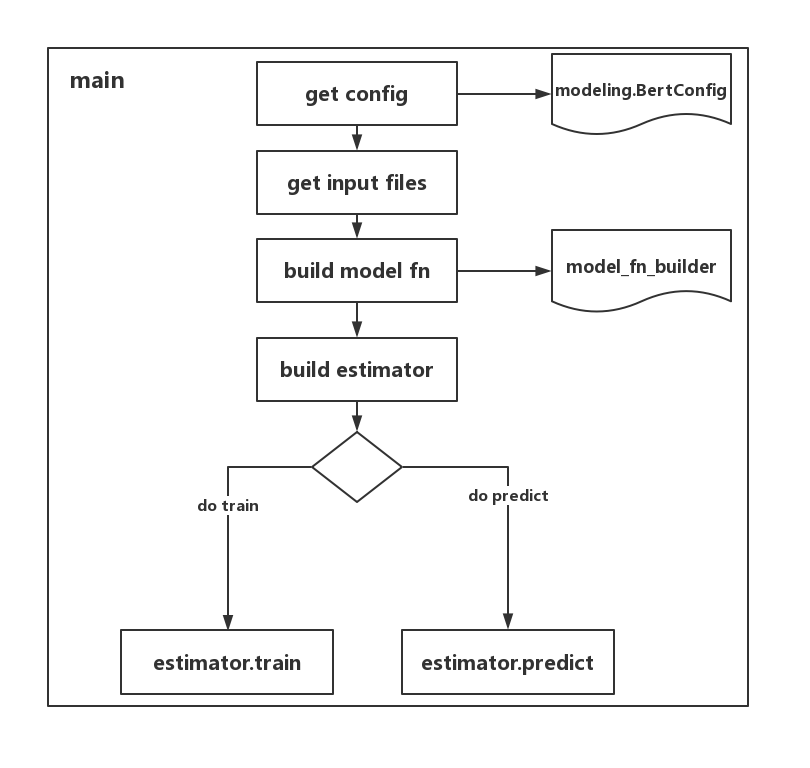
在bert_config_file文件中配置各个参数,例如attention_probs_dropout_prob和directionality等,config文件在BERT提供的预训练模型中。
结构图中以get input files表示整个的输入数据处理部分,不同于早期版本的数据处理过程,当前的TF版本将数据转化为features用于训练。所以需要建立相应的结构体承接数据,并建立对应的数据处理方法,最后转化为features,下表中convert_exps_to_features为convert_examples_to_features简写。
SimHash和MinHash算法主要应用于海量文本查重,两者都属于局部敏感哈希(Locality-Sensitive Hashing, LSH)算法,而LSH又是近似最近邻查找(Approximate Nearest Neighbor, ANN)中的一类算法,其主要思想是利用降维和索引,加快查找过程。
算法的过程如下图所示:
具体过程为:
TextRank算法可以用于提取文本关键词和生成摘要,其思想来源于PageRank算法。Google的两位创始人在斯坦福大学读研期间从事网页排序研究时,受到学术界对学术论文重要性的评估方法(论文引用次数)启发,提出了PageRank算法。PageRank算法的核心思想比较直观:
将网页之间的链接抽象为一张有向图,如下图所示: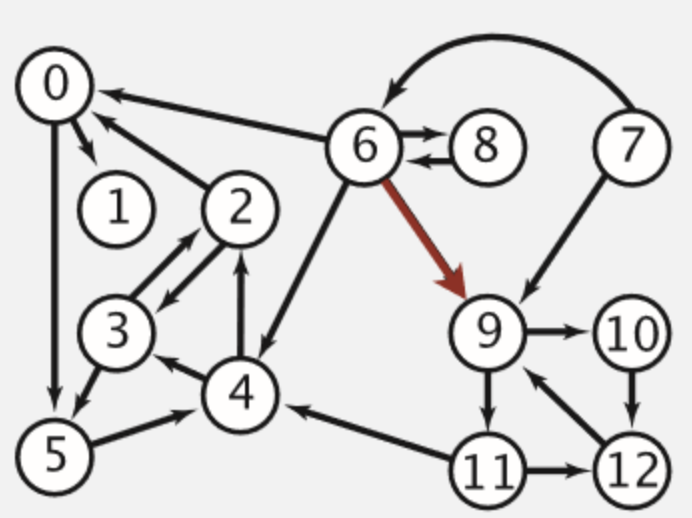
Tensorflow Serving是Google官方提供的模型部署方式,正确导出模型后,可一分钟完成部署(官方广告)。TF1.8后,Tensorflow Serving支持RESTfull API和grpc的请求方式,模型部署完成后可很方便的利用post请求进行测试。
框架分为模型训练、模型上线和服务使用三部分。模型训练与正常的训练过程一致,只是导出时需要按照TF Serving的标准定义输入、输出和签名。模型上线时指定端口号和模型路径后,通过tensorflow_model_server命令启动服务。服务使用可通过grpc和RESTfull方式请求。
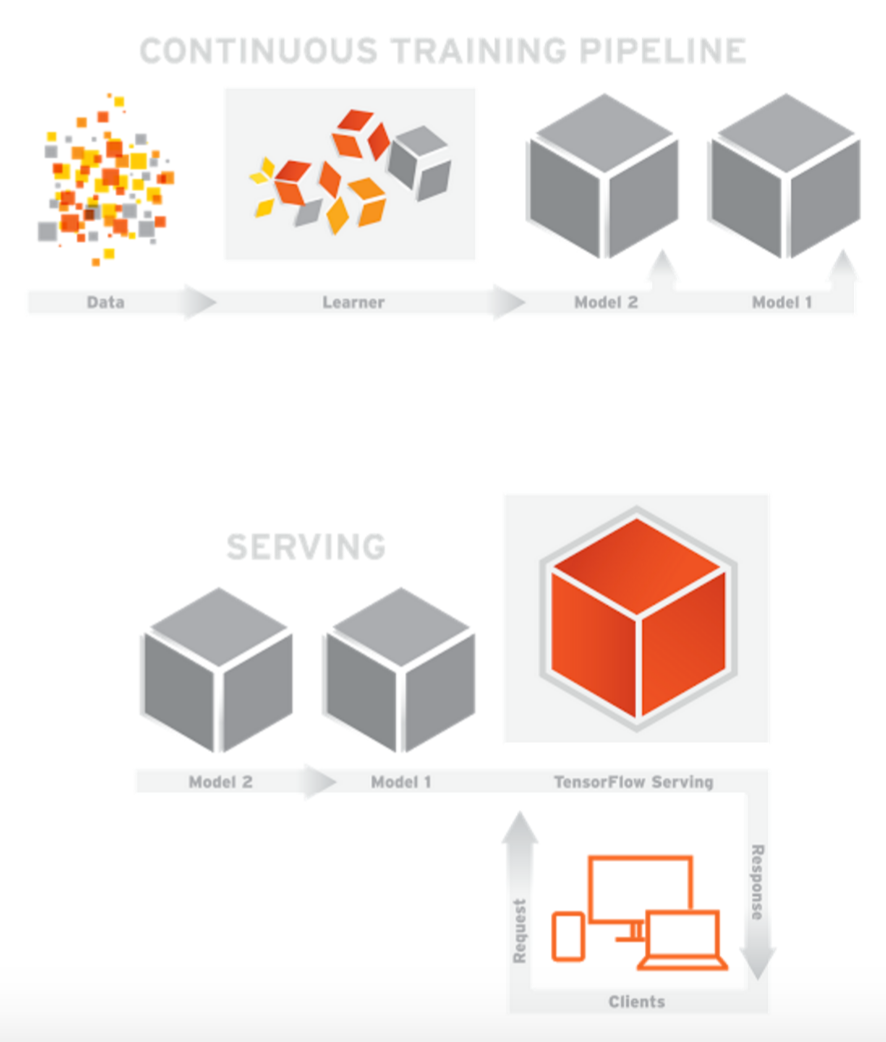
TF Hub是一个通过复用Tensorflow models来完成迁移学习的模型库,目前有自然语言、图像和视频三大类,具体可参考下面链接(部分页面需要翻墙):
首先对人物图片进行人脸识别,然后利用tfhub中inception v3模型提取feature vector,最后使用SVR模型完成基于人脸的BMI指数预测。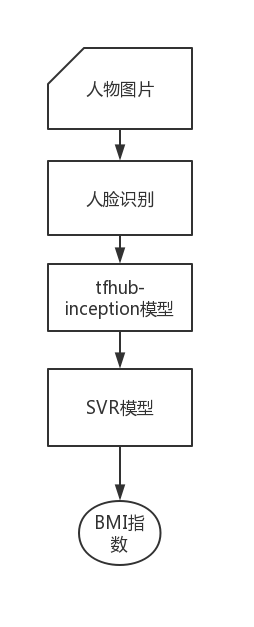
这里介绍golang版本解决方案,python的资源丰富,例如face_recognition等。go-face提供了纯go版本的人脸识别功能,不需要安装opencv等复杂的环境依赖,相关的依赖也可以通过apt-get方式快速安装,值得注意的是其需要人脸识别的模型文件shape_predictor和dlib_face_recognition,具体介绍可以参考其github主页。
2018年10月谷歌AI团队发布BERT模型,在11种NLP任务测试中刷新了最佳成绩,一时风头无两。自然语言处理领域近两年最受关注,并且进展迅速的当属机器阅读理解,其中斯坦福大学于2016年提出的SQuAD数据集对于推动Machine Comprehension的发展起到了巨大的作用。SQuAD 1.0发布时,Google一直没有出手,微软曾长期占据榜首位置,阿里巴巴也曾短暂登顶。2018年1月3日微软亚洲研究院提交的R-NET模型在EM值(Exact Match表示预测答案和真实答案完全匹配)上以82.650的最高分领先,并率先超越人类分数82.304。而当谷歌一出手,便知有没有,目前SQuAD排行榜上已经被BERT霸屏,排行前列的模型几乎全部基于BERT。关于通用语言模型的介绍,可以参考另一篇翻译的博客,以及张俊林老师的介绍,参考链接附在本文末尾。
谷歌已开放源码:
摘要生成主要有extractive和abstractive两种方式,抽取式直接从原文中抽取整个句子进行组合,生成摘要。而抽象式则类似人类书写摘要的方式,可产生文中不存在的词语。抽取式更为简单,并且在语法和准确性方面可以保证基本的效果。但如果希望拥有神奇的能力,例如 “paraphrasing, generalization, or the incorporation of real-world knowledge”,就需要抽象式模型了。本文的工作对2016年提出的copyNet进行了许多改进,关于copyNet的介绍可以参考:
copyNet在解码阶段会出现多次重复的情况,Pointer-Generator Networks使用Coverage mechanism来解决这个问题,下面具体介绍模型实现细节。
Seq2Seq模型在自然语言处理领域应用广泛,例如机器翻译、句子生成和单轮对话。从更为广泛的角度看,其属于Encoder-Decoder网络,但Seq2Seq模型对于实体名字、谚语和成语在decoder时往往表现欠佳,例如:
原文:第76届金球奖,布莱德利·库珀、LadyGaga主演的《一个明星的诞生》歌曲《Shallow》获得最佳原创歌曲。
翻译:在第76届金球奖上,布莱德利·库珀和LadyGaga主演的歌曲《浅滩》获得了最佳原创歌曲奖。(zh-en-zh)
在对于歌曲名字的翻译上出现了错误,而在人工翻译中一般会将这些词语“照抄”,也就是本文主要说明的copy机制。
目前知识图谱问答主流方法有基于语义解析、信息抽取和向量建模三种,近些年来流行的深度学习技术主要在向量建模方面进行改进。截止2016年,在公开数据集WebQuestion上表现最好的模型主要是对语义解析进行了改进,将问题转换为查询图,并利用CNN进行特征提取和相似性计算。
注:本文中的图片均引用自相关论文和资料。
语义解析的主要方法是将自然语言句子转化为逻辑语句,然后通过数据库查询得到答案,Jonathan Berant[1]发表于EMNLP 2014的文章是一个典型例子。下面以一个具体问题为例子,简述一下整体过程。给定一个自然语言的问题:
“Where was Obama born?”
首先利用语义解析工具对问题进行解析,如下图所示: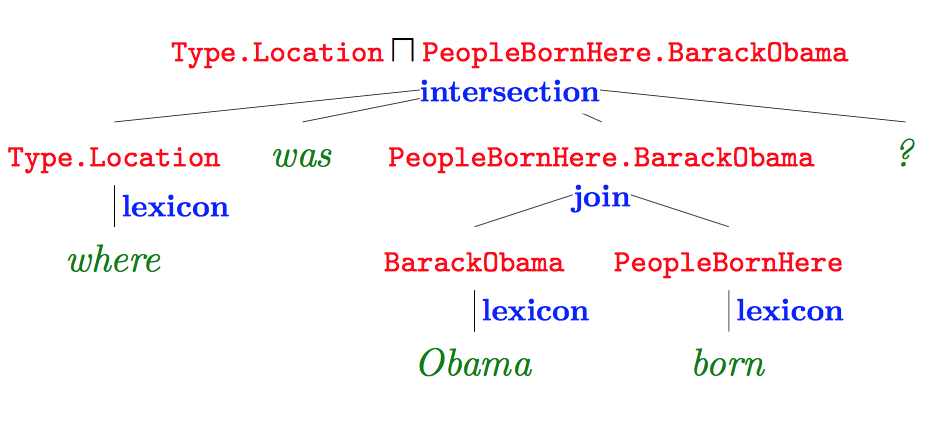
图中红色部分为逻辑形式,绿色部分为原始问题,蓝色部分表示词汇映射和构建对应的操作,语义解析树根节点即为解析结果。
模型的训练主要是针对每一种语义解析结果的分类概率,对于训练数据问题-答案对,通过最大化log-likelihood损失函数,利用随机梯度下降对参数进行更新。
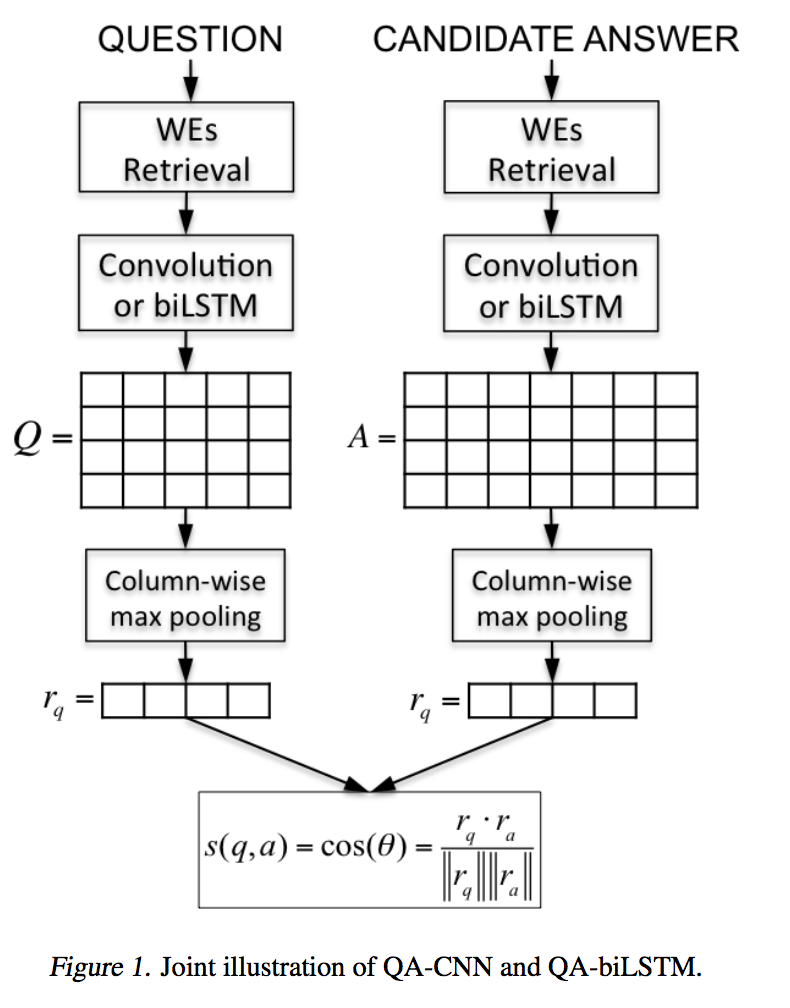
机器问答是自然语言处理领域的核心任务,一个典型的开放式问答系统分为三个部分:(1) 问题分析和候选篇章检索;(2) 候选篇章排序;(3)答案选择。本文主要关注答案选择部分,传统的模型大多基于特征工程实现,使用词法、句法和语法等特征,需要额外的资源,一旦外部工具出错,模型性能会受到影响,并且外部资源的获得也需要付出一些成本。深度学习模型可以自动学习这些特征,通过将句子映射到一个向量空间,然后在隐藏空间对问题和候选答案匹配完成答案选择,在众多数据集的测试结果均优于传统模型。本文从基本模型Siamese Network开始、逐个介绍了模型的改进版本Attention Network和Compare-Aggregate Network,随后对匹配函数选择和如何利用句子不相似部分两个点进行了说明。此外为方便对各模型进行比较,文章最后收集了各模型在WikiQA数据集上的实验结果并进行了展示。
注:本文所使用的图片均来自对应论文。
Siamese网络[1]的特点是包含两路结构非常相似的网络,网络之间的参数共享,在最后进行连接,适用于计算两路输入信息的相似性。
dos Santos在根据Query选择Candidate answer一文[2]中使用了Siamese网络作为Baseline。模型如下图所示: